I’ve put online (on HAL) the manuscript I’ve submitted to PowerTech 2021 (⚠ not yet accepted [Edit: it was eventually accepted. Presentation video is available]). It discusses the modeling of energy storage losses. The question is how to model these losses using convex functions, so that the model can be embedded efficiently in optimal energy management problems.
Key idea
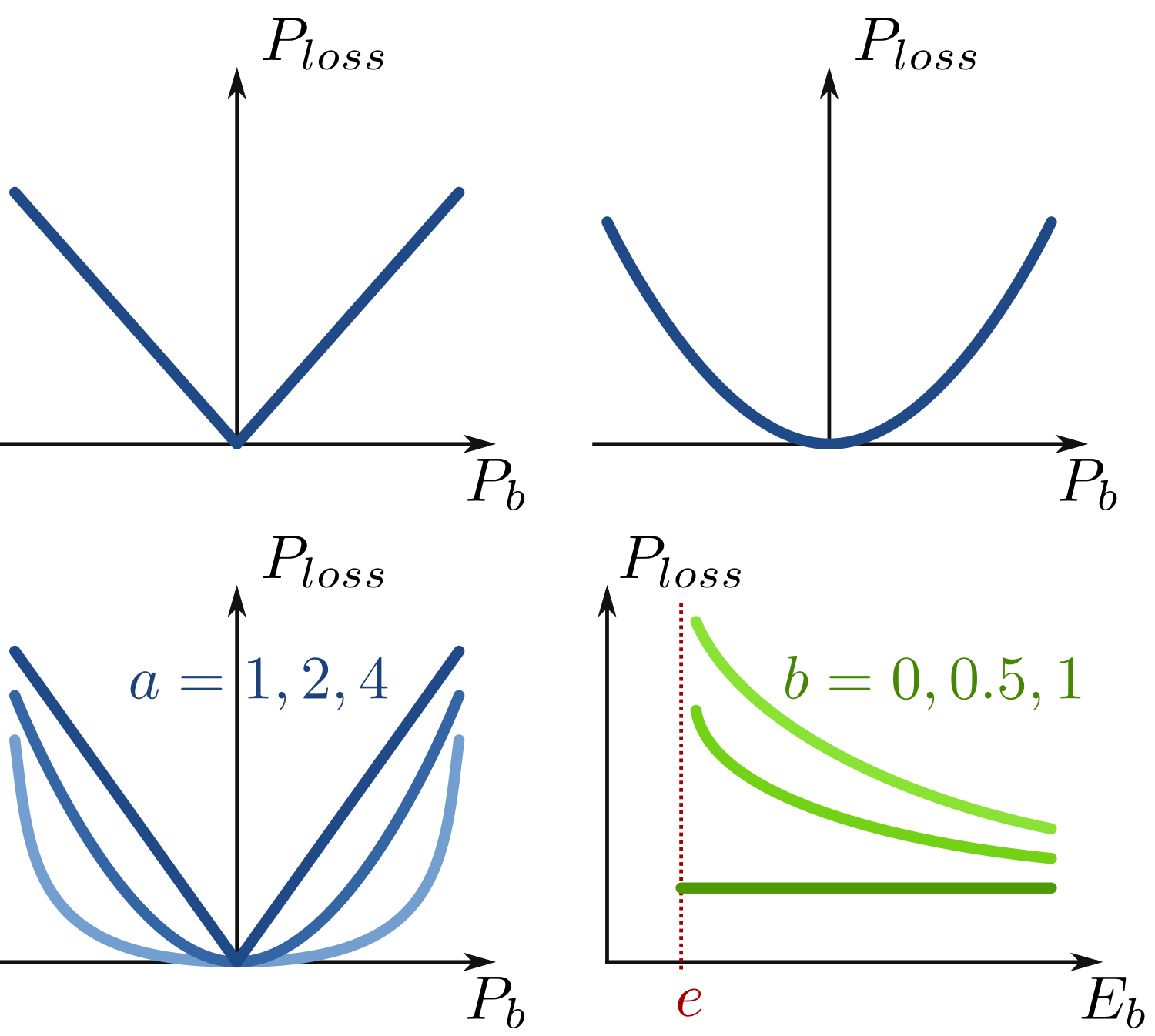
This is possible thanks to a constraint relaxation: losses are assumed to be greater than (≥) their expression, rather than equal (=). With a convex loss expression, the resulting constraint is convex. In applications where energy losses tend to be naturally minimized, this works great. This means that the inequality is tight at the optimum: losses are eventually equal to their expression. Notice that in applications where dissipating energy can be necessary at the optimum, this relaxation can fail: losses are strictly greater than their expression, meaning that there are extraneous losses!
Germination
I’ve had this topic in mind for some years now, with early discussion at PowerTech 2015 with Olivier Megel (then at ETH Zurich). Fast-forwarding to spring 2020, I had a nice exchange with Jonathan Dumas and Bertrand Cornélusse (Univ. Liège) which provided me with related references in the field of power systems.
After some experiments at the end of the last academic year, I’ve assembled these ideas during the autumn (conference deadline effect), realizing that, as often, there was quite a large amount of literature on the topic. Papers that I would have stayed unaware of, if not writing the introduction of this paper! Still, I found the subject was not exhausted (also a common pattern) so that I could position my ideas.
Contribution
I believe that the contribution is:
Describe the relaxation of storage losses in a unified way which handles the various existing loss models
Provide a simple continuous family of nonlinear convex loss expressions which can depend on both storage power and energy level.
The typical effect being covered by the loss model I propose is when power losses (proportional to the squared power) varies with the state of charge (typically at the very end of charge or discharge). In short, it unites and generalizes classical loss models, while preserving convexity.
I don’t think this will revolutionize the field, but hopefully it can help people in energy management using physically more realistic battery models, while still keeping the computational efficiency of convex optimization.
Classical loss models (above) are piecewise linear (e.g. constant efficiency) or quadratic in storage power (Pb). Few models also depends on the storage energy level (Eb). The proposed model unites and generalizes classical loss models, while preserving convexity. See manuscript for the meaning of parameters a and b.
More than a year after the start of its development, I’m now pushing the “final” version of my tiny web app “Electric vs Thermal vehicle calculator, with uncertainty”. It allows comparing the ecological merit of electric versus thermal vehicles (greenhouse gas emissions only) on a lifecycle basis (manufacturing and usage stages).
Compared to alternatives (featuring nicer designs), this app enables changing the value all the inputs to watch their influence, thus the name “calculator”. Of course, a nice set of presets is provided. Also, it is perhaps the only comparator of this kind to handle the uncertainty of all these inputs: it uses input ranges (lower and upper bounds) instead of just nominal values. Therefore, one can check how robust is the conclusion that electric vehicles are better than thermal counterparts (spoiler: it is, unless using highly pessimistic, if not biased, inputs).
History of this app
I started this app in spring 2019, after I came across the blog post “Electric car: 697,612 km to become green! True or false?” by Damien Ernst (Université de Liège). At that time, I was not familiar with the lifecycle analysis of electric vehicles (EVs) and the article seemed at first pretty convincing. I was surprised to discover the sometimes violent feedback Pr. Ernst received. Fortunately, I also found more constructive responses, e.g. from Auke Hoekstra (Zenmo, TU Eindhoven), which I soon realized to be a serial myth buster on the question of EV vs thermal vehicles(*).
I quickly realized that the key question for making this comparison is the choice of input data (greenhouse gas emissions for battery manufacturing, energy consumption of electric and thermal vehicles …). Indeed, with a given set of inputs, the computation of the “distance to CO₂ parity” is simple arithmetic. I created a calculator app which implements this computation. This enables playing with the value of each input to see its effect on the final question: “Are EVs better than thermal vehicles?”.
Handling uncertainty
While discussing Ernst’s post with colleagues, I got feedback that perhaps the first big issue with his first claim “697,612 km to become green” is that conveys a false sense of extreme precision. Indeed, high uncertainty around some key inputs prevents giving so many significant digits. And indeed, it is because several, if not all, inputs are open to discussion (fuel consumption: real drive or standard tests, electricity mix for EV charging: 100% coal or French nuclear power…?) that there are all these clashing newspaper articles and Twitter discussions piling up!
Searching for good quality inputs
When I started the app, I thought I would save the time to research for good sets of inputs, since it is a calculator where the user can change all the inputs to his/her choice. This was a short illusion because I soon realized that the app would be much better with a set of reasonable choices (presets), so that I needed to do the job anyway. This is in fact pretty time consuming, since there is a need for serious research for almost each input. Now, I don't consider this work finished (it cannot!), but I think I've spent a fair attention and found reliable sources (e.g. meta-analyses) to each input. My choices are documented at the end of the presentation page.
In this process, I've learned a lot, and the main meta knowledge I take away is that inputs need to be fresh. Indeed, like in the field of renewables, the main parameters of EV batteries are changing fast (increasing size, decreasing per kWh manufacturing emissions…) and so is the European power sector (e.g. the emissions per kWh for EV charging).
(*) Auke Hoekstra was perhaps irritated to endlessly repeat his arguments everywhere, so he collected his key methodological assumptions in a journal paper “The Underestimated Potential of Battery Electric Vehicles to Reduce Emissions”, Joule, 2019, DOI: 10.1016/j.joule.2019.06.002 (with an August 2020 update written for the green party Bundestag representatives).
À cause (ou grâce) au confinement, j’ai enseigné à distance mon cours d’électrotechnique « Énergie Électrique » de mai–juin 2020.
Pour tenter de « garder dans le rythme » les étudiantes et les étudiants au fil des 5 semaines du cours, j’ai créé une série de questions d’entrainement (majoritairement des QCM) pour la plateforme Moodle. Les voici à présent sous forme d’archive à télécharger (texte + fichier directement importable dans Moodle), pour d’éventuel·le·s collègues intéressé·e·s.
This is just a short note that may be useful to other people with a similar setup. I just installed a fresh Windows 10 virtual machine (VM) on my Linux system (Debian 10 “buster”, with VirtualBox 6.1.4 coming from Lucas Nussbaum unofficial VirtualBox repository).
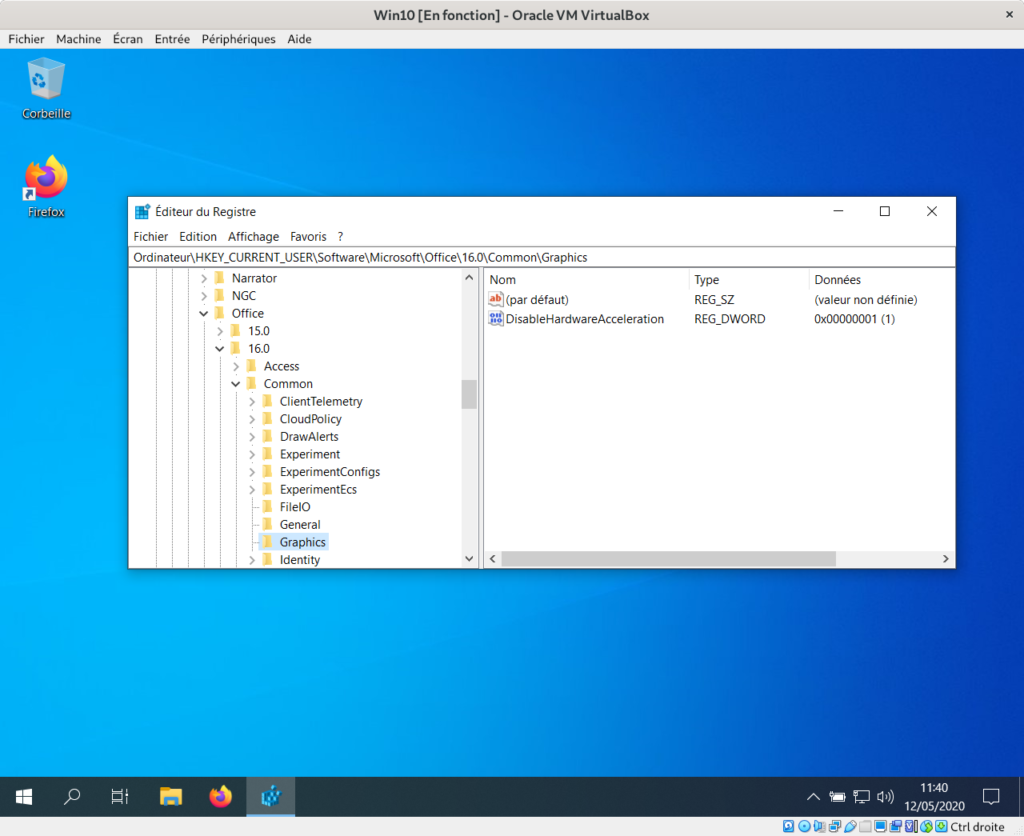
One of the main objectives of this VM is to have Microsoft Office 365 for my work. Unfortunately, I faced a “blank window” issue which makes it totally unusable! First symptoms appeared around the end of the installation setup, but I didn't pay much attention since it still completed fine. However, at the first launch of Word (or PowerPoint or Excel), I got two blank windows: on the background a big white window which was probably Word, and on the foreground a smaller blank window, perhaps the license acceptation dialog, where I was probably supposed to press Yes if only I could see the button...
Now, I made some searches, and I did find some similar symptoms, but no adequate problem solutions. Only, I learned that the problem may come from Office use of hardware acceleration for display. Since I had previously activated the 3D hardware acceleration in the VM settings (it sounded like a good thing to activate), I tried to uncheck it, with no effect.
Then, it's possible to disable Office hardware acceleration, and this worked for me. However, among the three ways to do it I found, only the more complicated worked (regedit). Here are the three options:
Opening “Word Options/Advanced tab” to check the box “disable hardware graphics acceleration”: obviously impossible when Word starts with a blank screen...
Starting Office in safe mode: I had read this would temporarily disable hardware acceleration so that I could use option 1
Disabling hardware acceleration by manually editing the registry (source: getalltech.com)
In the end, only the arcane option 3 worked. As mentioned in the source, on my fresh Windows 10 setup, the subkey Graphics needs to be created inside HKEY_CURRENT_USER \Software \Microsoft \Office \16.0 \Common (the source says that version “16.0” is for Office 2016, but it seems Office 365 in 2020 is also version 16). And then create the DWORD value DisableHardwareAcceleration and set its value to 1.
Disabling Office 365 hardware graphics acceleration using Windows Registry editor (regedit)
After a reboot (is it necessary?), I could indeed run Word 365 properly and accept all the first run dialogs. It seems to run fine now. Phew!
Office Word 365, on Windows 10, inside VirtualBox, under Debian... quite a few spatial prepositions!
These last weeks, I’ve read William S. Cleveland book “The Elements of Graphing Data”.
I had heard it’s a classical essay on data visualization.
Of course, on some aspects, the book shows its age (first published in 1985), for example
in the seemingly exceptional use of color on graphs.
Still, most ideas are still relevant and I enjoyed the reading.
Some proposed tools have become rather common, like loess curves.
Others, like the many charts he proposes to compare data distributions (beyond the common histogram),
are not so widespread but nevertheless interesting.
One of the proposed tools I wanted to try is the (Cleveland) dot plot.
It is advertised as a replacement of pie charts and (stacked) bar charts, but with a greater visualization power.
Cleveland conducted scientific experiments to assess that superiority, but it’s not detailed in the book (perhaps it is in the Cleveland & McGill 1984 paper).
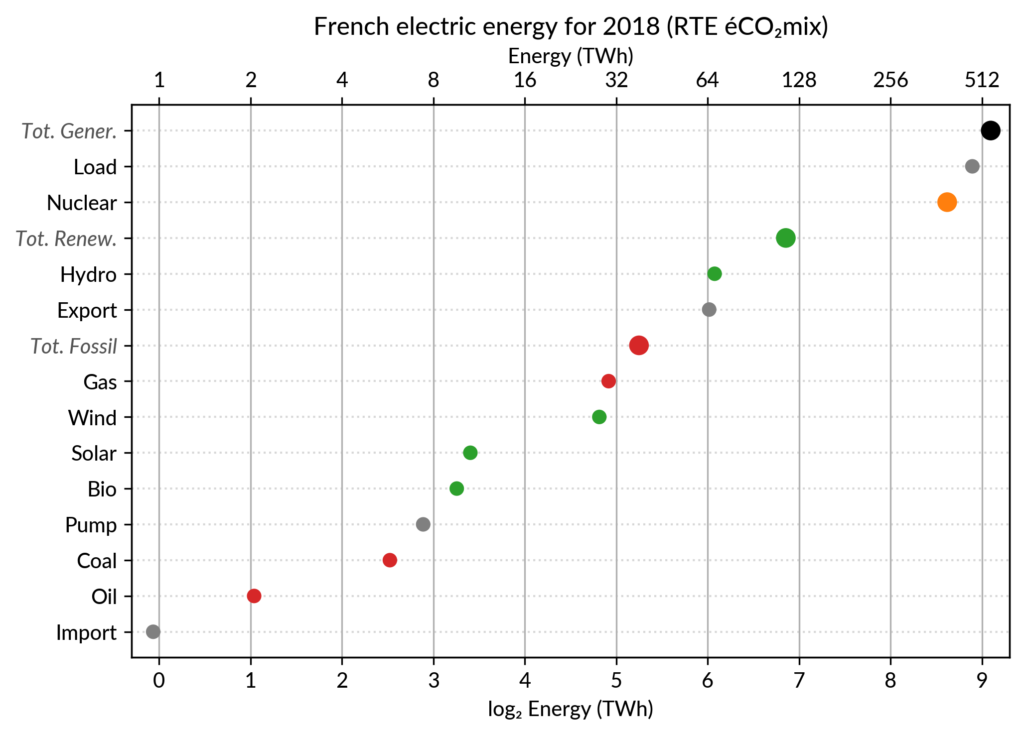
I’ve explored the visualization power of dot plots using the French electricity data from RTE éCO₂mix (RTE is the operator of the French transmission grid).
I’ve aggregated the hourly data to get yearly statistics similar to RTE’s yearly statistical report on electricity (« Bilan Électrique »).
The case for dot plot
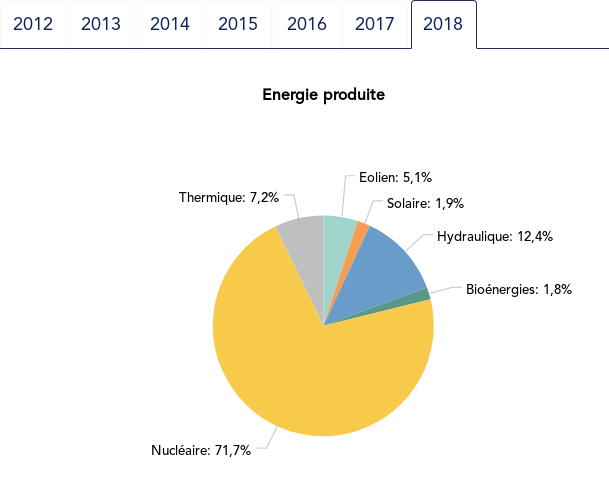
Such yearly energy data is typically represented with pie charts to show the share of each category of power plants. This is RTE’s pie chart for 2018 (from the Production chapter):
However, Cleveland claims that the dot plot alternative enables more efficient reading of single point values
and also easier comparison of different points together. Here is the same data shown with a simple dot plot:
I’ve colored plant types by three general categories:
Fossil (gas, oil and coal) in red
Renewable (hydro, wind, solar and bioenergy) in green
Nuclear in orange
Subtotals for each category are included.
Gray points are either not a production (load, exports, pumped hydro) or cannot be categorized (imports).
Compared to the pie chart, we benefit from the ability to read the absolute values rather than just the shares.
However, how to read those shares?
This is where the log₂ scale, also promoted by Cleveland in his book, comes into play. It serves two goals. First, like any log scale, it avoids the unreadable clustering of points around zero
when plotting values with different orders of magnitude.
However, Cleveland specifically advocates log₂ rather than the more
common log₁₀ when the difference in orders of magnitude is small (here
less than 3, with 1 to 500 TWh) because it would yield a too small
number of tick marks (1, 10, 100, 1000 here) and also because log₂ aids reading ratios of two values:
a distance of 1 in log₂ scale is a 50% ratio
a distance of 2 in log₂ scale is a 25% ratio
…
Still, I guess I’m not the only one unfamiliar with this scale, so I made myself a small conversion table:
Δlog
ratio a/b (%)
ratio b/a
0.5
71% (~2/3 to 3/4)
1.4
1
50% (1/2)
2
1.5
35% (~1/3)
2.8
2
25% (1/4)
4
3
12%
8
4
6%
16
5
3%
32
6
1.5%
64
As an example, Wind power (~28 TWh) is at distance 2 in log scale of
the Renewable Total, so it is about 25%. Hydro is distant by less than
1, so ~60%, while Solar and Bioenergies are at about 3.5 so ~8% each.
Of course, the log scale blurs the precise value of large
shares. In particular, Nuclear (distant by 0.5 to the total generation)
can be read to be somewhere between 65% and 80% of the total, while the
exact share is 71.2%. The pie chart may seem more precise since
the Nuclear part is clearly slightly less than 3/4 of the disc.
However, Cleveland warns us that the angles 90°, 180° and 270° are
special easy-to-read anchor values whereas most other values are in fact
difficult to read.
For example, how would I estimate the share of Solar in the pie chart
without the “1.9%” annotation? On the log₂ scaled dot plot, only a
little bit of grid line counting is necessary to estimate the distance
between Solar and Total Generation to be ~5.5, so indeed about 2% (with
the help of the conversion table…).
The bar chart alternative?
Along with the pie chart, the other classical competitor to dot plots is the bar chart.
It’s actually a stronger competitor since it avoids the pitfall of the poorly readable angles of the pie chart.
I (with much help from Cleveland) see three arguments for favoring dots over bars.
The weakest one may be that dots create less visual clutter. However, I see a counter-argument that bars are more familiar to most viewers, so if it were only for this, I may still prefer using bars.
The second argument is that the length of the bars would be meaningless.
This argument only applies when there is no absolute meaning for the
common “root” of the bars. This is the case here with the log scale. It
would also be the case with a linear scale if, for some reason, the zero
is not included.
The third argument is an extension of the first one (better clarity) in the case when several data points for each category must be compared. Using bars there are two options:
drawing bars side by side: yields poor readability
stacking bars on top of each other (if the addition makes
sense like votes in an election): makes a loss of the common ground,
except for the bottom most bars (of left most bars when using the
horizontal layout like here)
This brings me to the case where dot plots shine most: multiway dot plots.
Multiway dot plots
The compactness of the “dot” plotting symbol (regardless of the
actual shape: disc, square, triangle…) compared to bars allows
superposing several data points for each category.
Cleveland presents multiway dot plots mostly by stacking horizontally
several simple dot plots. However, now that digital media allows high
quality colorful graphics, I think that superposition on a single plot
is better in many cases.
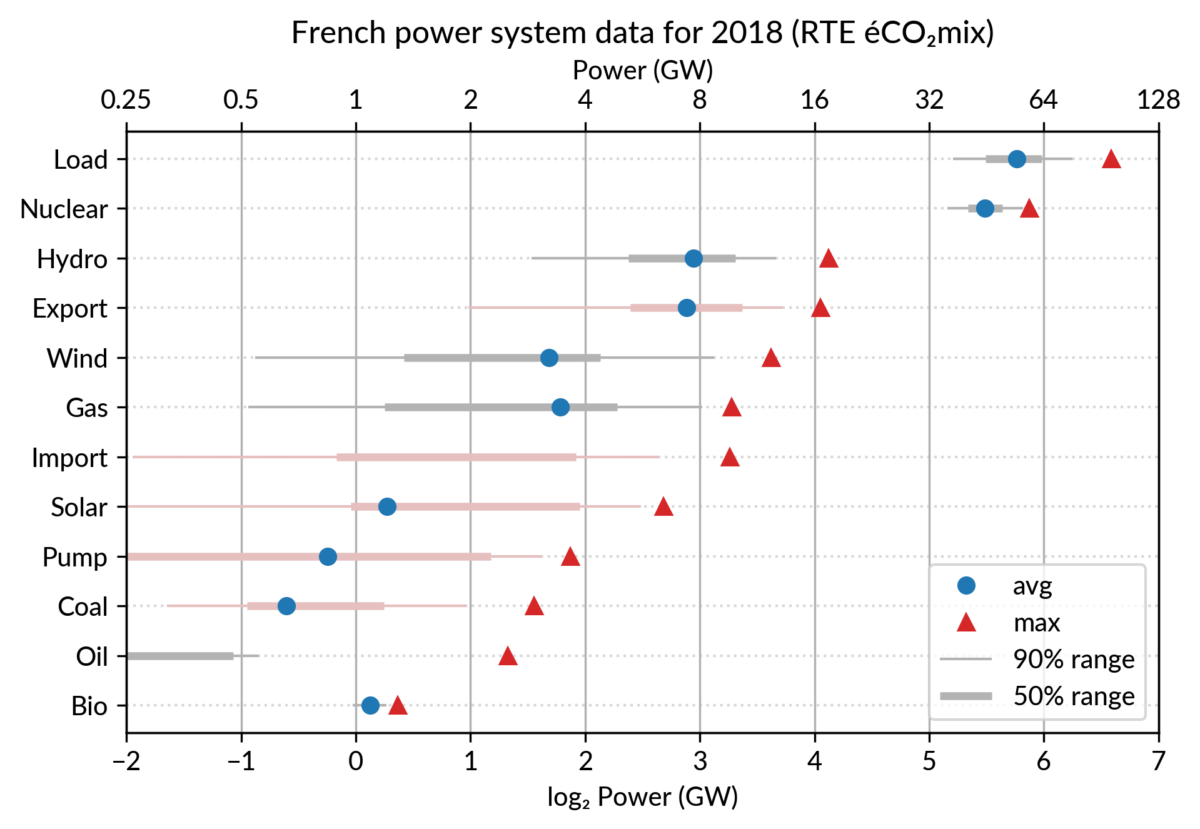
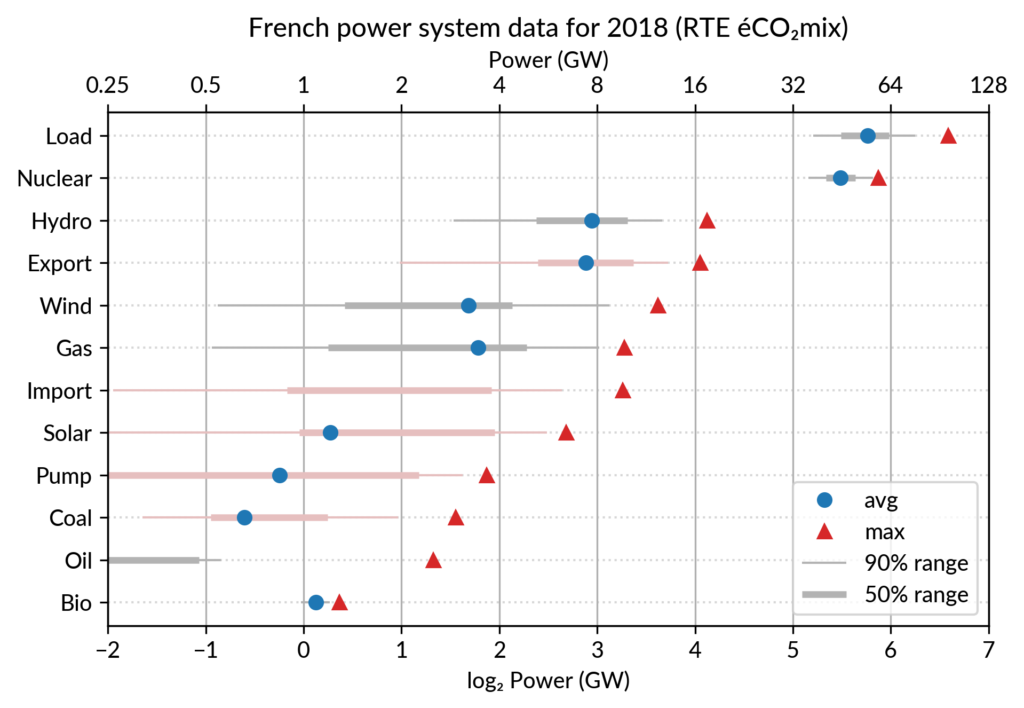
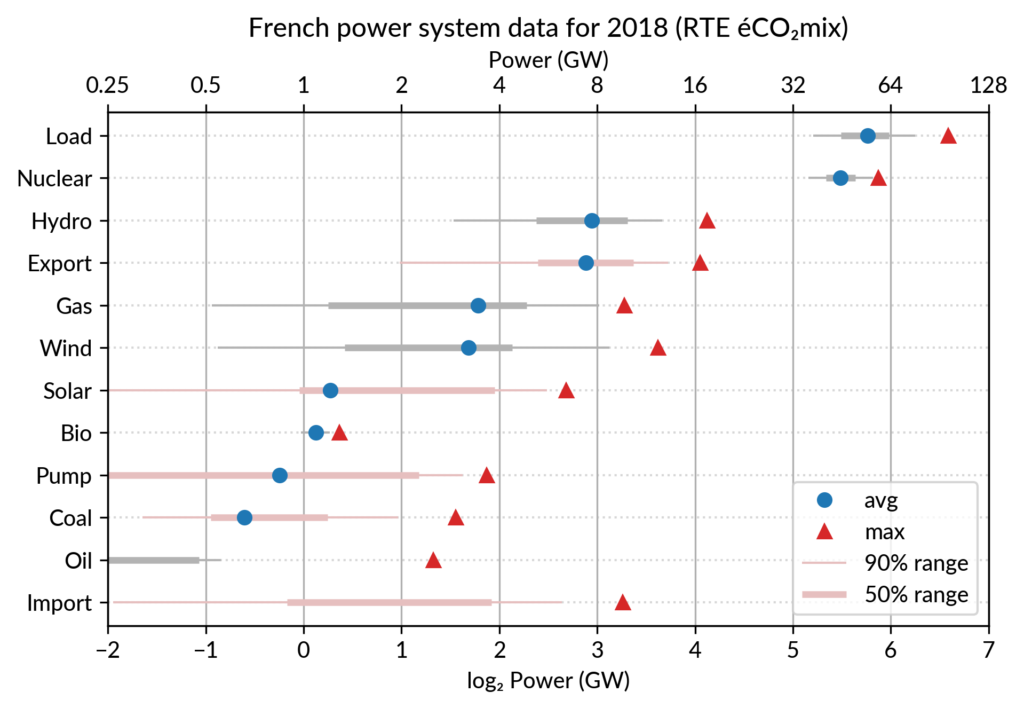
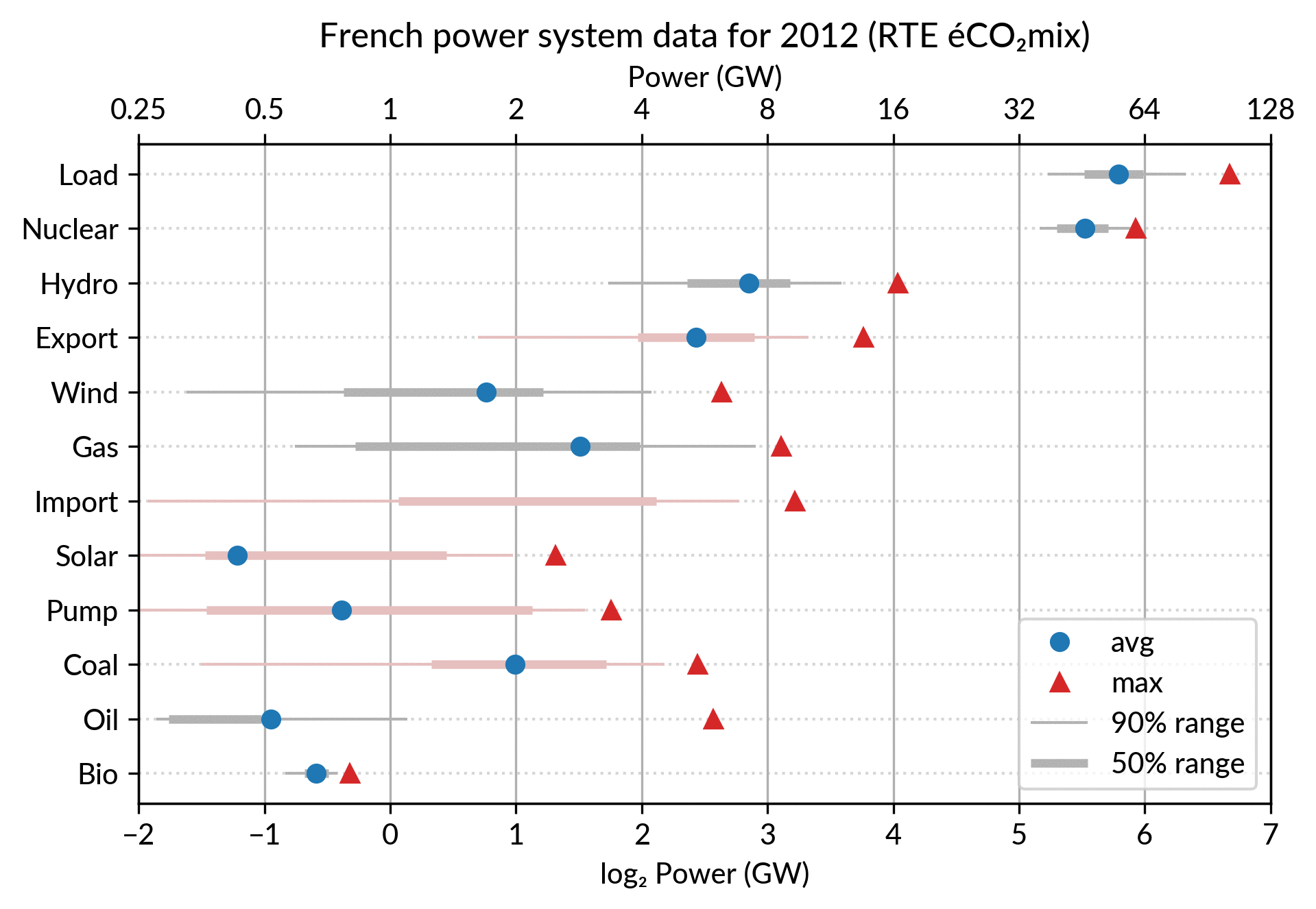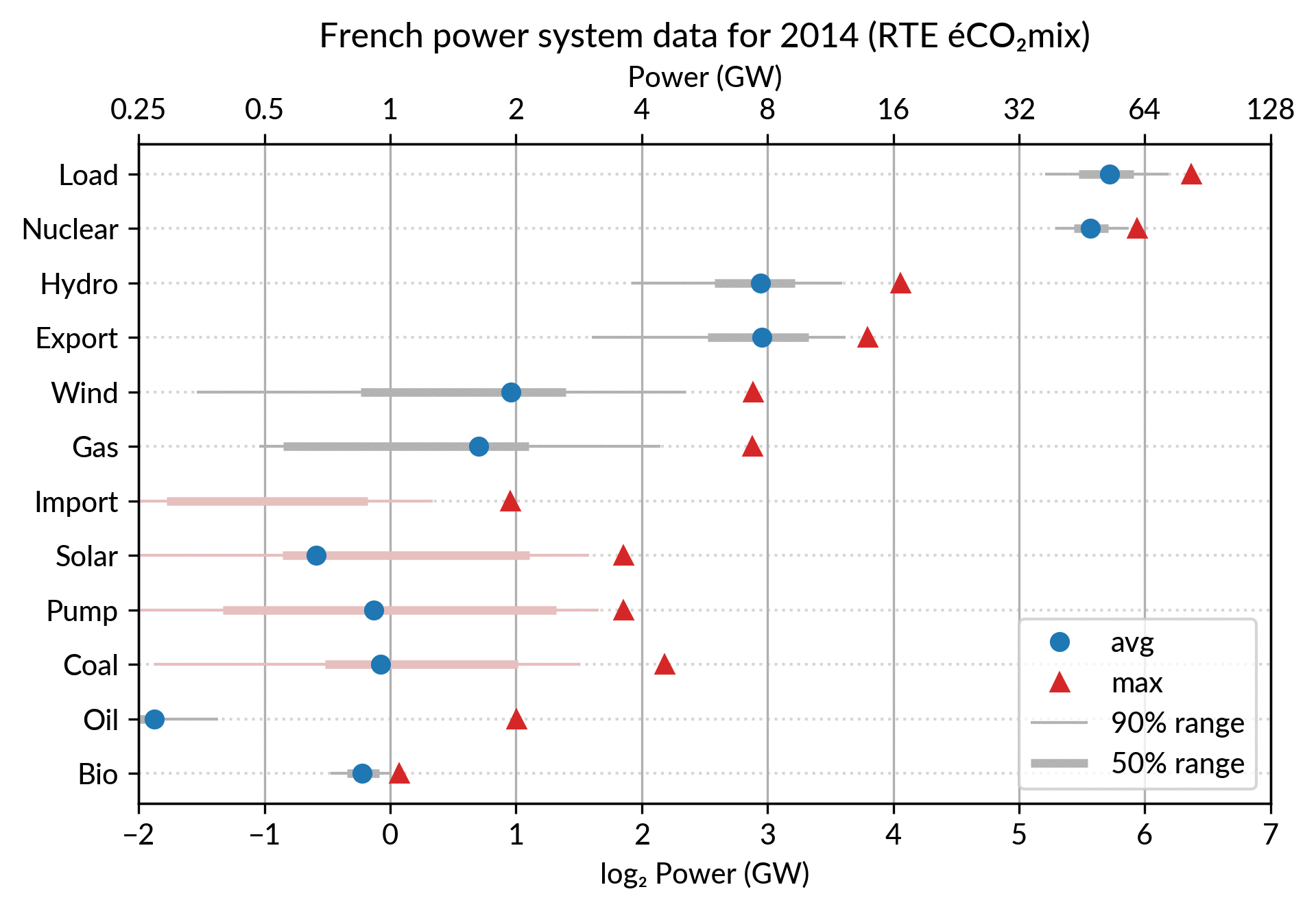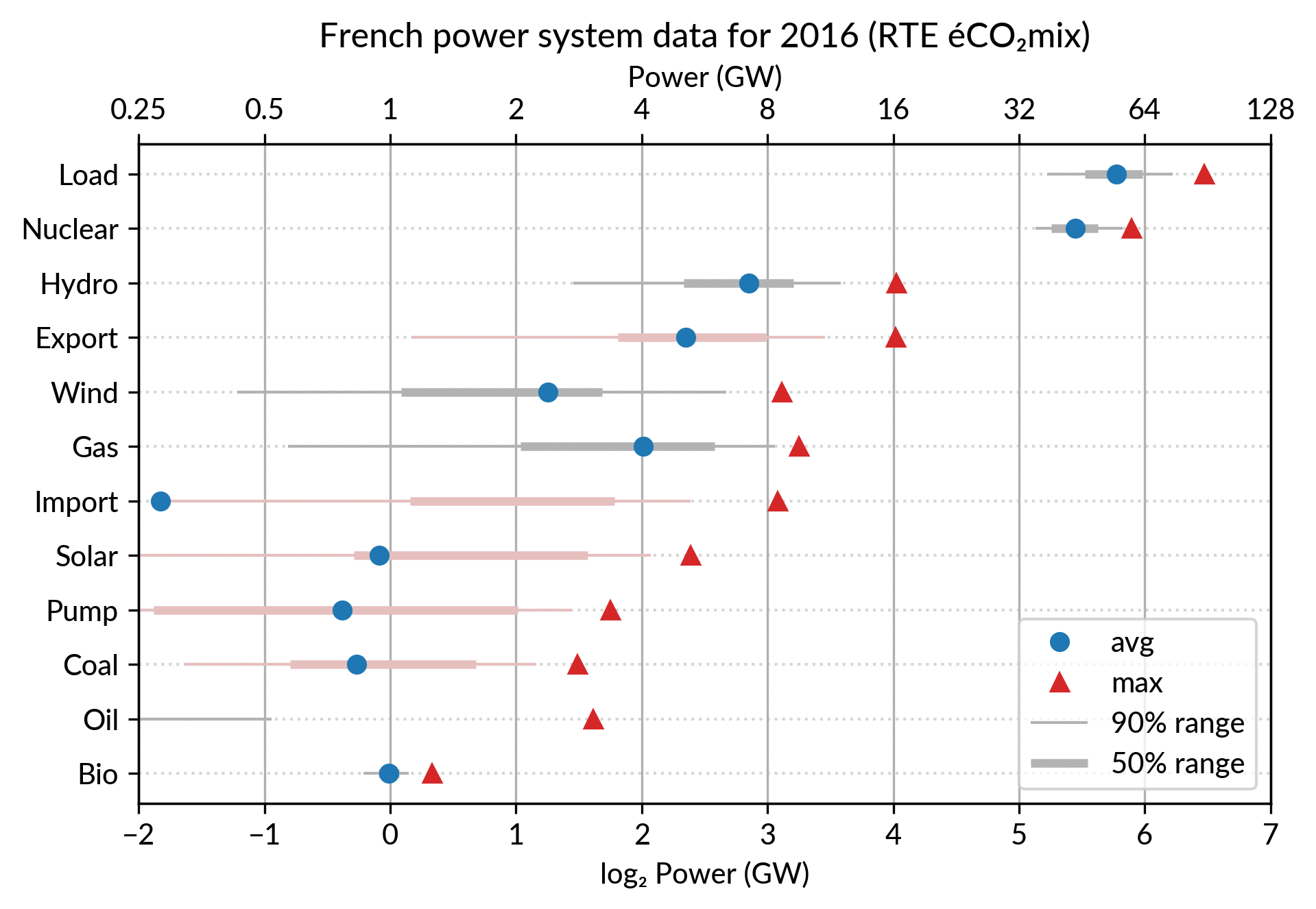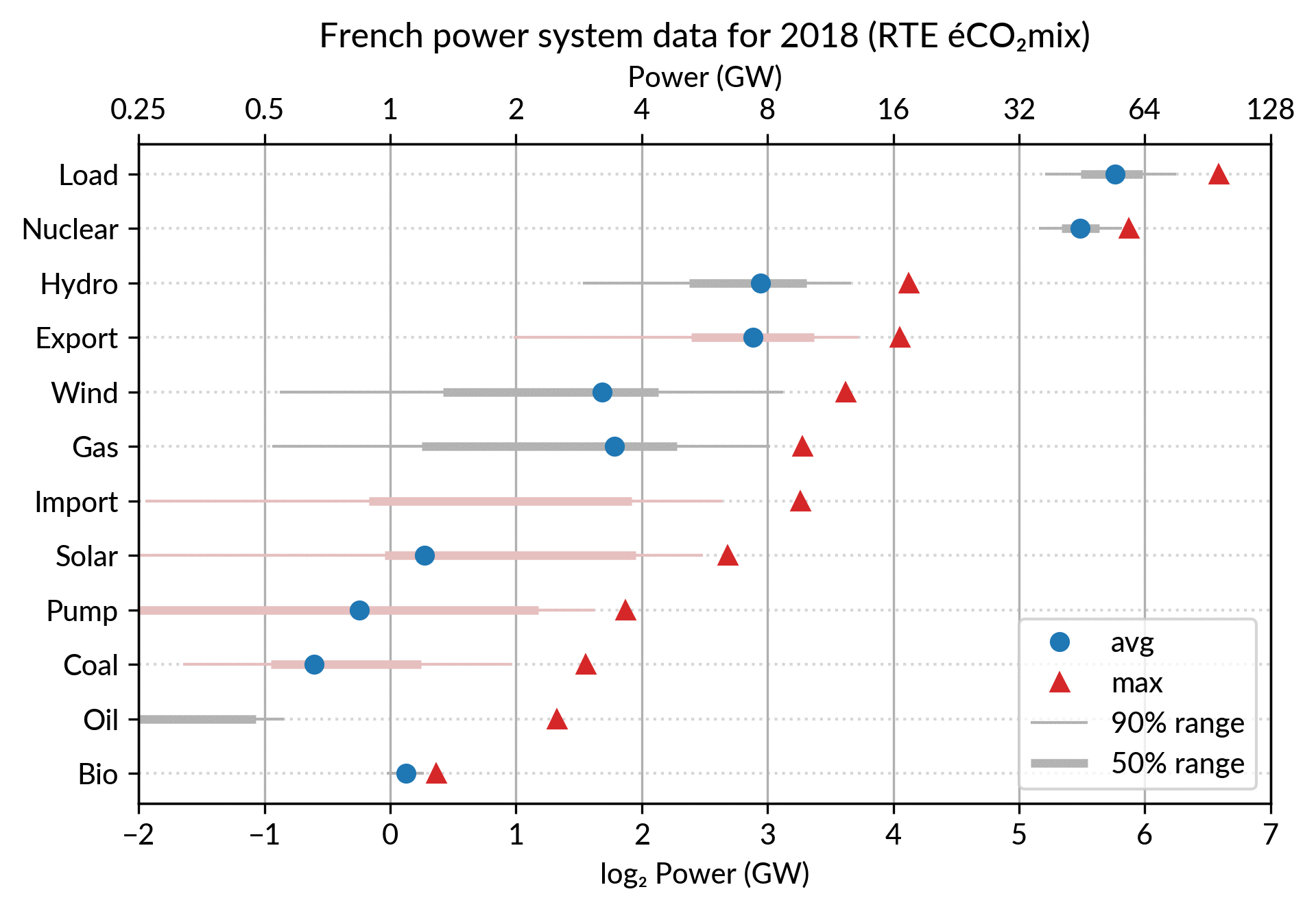
For the electricity data, I plot for each plant category:
the maximum power over the year (GW): red triangles
the average power over the year (GW): blue discs
The maximum power is interesting as a proxy to the power capacity.
The average power is simply the previously shown yearly energy production data, divided by the duration of the year.
The benefit of using the average power is that it can be superimposed
on the plot with the power capacity since it has the same unit.
Also, the ratio of the two is the capacity factor of the plant category, which is a third interesting information.
Since it is recommended to sort the categories by value (to ease comparisons), there are two possible plots:
plot sorted by the maximum powers (~capacity)
plot sorted by the average powers (equivalent to the cumulated energy for the year)
The two types of sorts are slightly different (e.g. switch of Wind and Gas) and I don’t know if one is preferable.
Adding some quantiles
Since I felt the superposition of the max and average data was
leaving enough space, I packed 4 more numbers by adding gray lines
showing the 90% and 50% range of the power distribution over the year.
With these lines, the chart starts looking like a box plot, albeit pretty non-standard.
However, I faced one issue with the quantiles: some plant categories
are shut down (i.e. power ≤ 0) for a significant fraction of the year:
Solar: 52% (that is at night)
Coal: 29% in 2018
Import: 96% (meaning that the French grid was net-importing electricity from its neighbors only 4% of the year in 2018)
To avoid having several quantiles clustered at zero, I chose to
compute them only for the running hours (when >0). To warn the
viewer, I drew those peculiar quantiles in light red rather than gray.
Spending a bit more time, it would be possible to stack on the right a
second dot plot showing just the shutdown times to make this more
understandable.
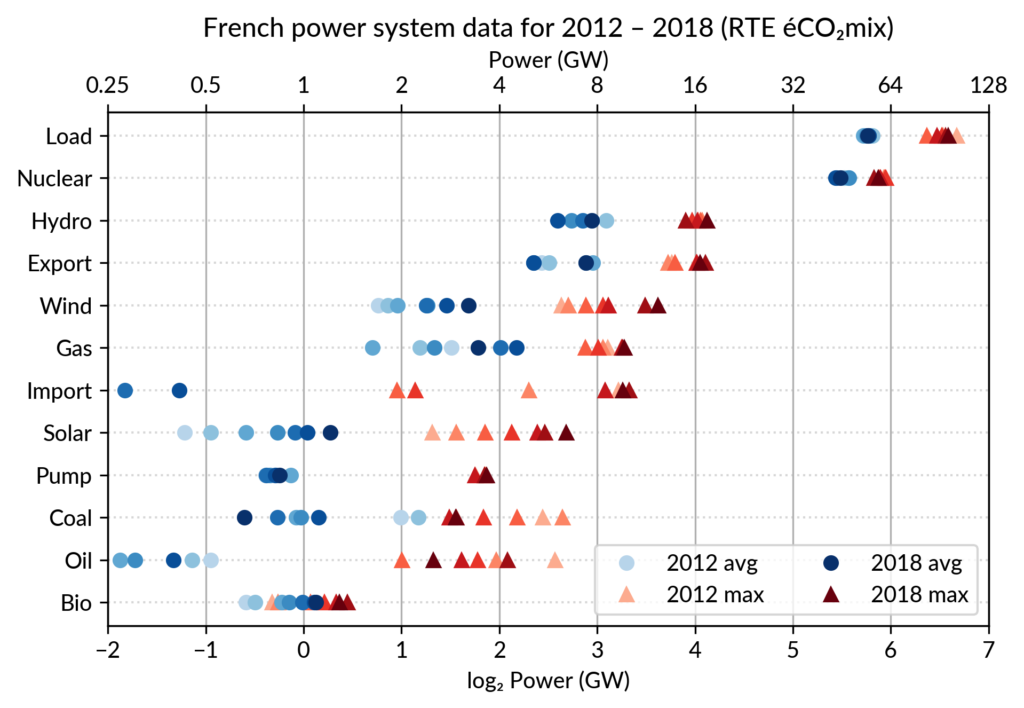
Animated dot plots
Again trying to pack more data on the same chart, I superimposed the statistics for several years.
RTE’s data is available from 2012 to 2018 (2019 is still in the making…) and the year can be encoded by the lightness of the dots.
I think it is possible to perceive interesting information from this
chart (like the rise of Solar and Wind along the drop of Coal), but it
may be a bit too crowded.
With only two or three years (e.g. 2012-2015- 2018), it is fine though.
A better alternative may be to use an animation. I tried two solutions:
GIF animation generated from the sequence of plots for each year
Interactive plot with the highlight of each year with mouse interaction using Altair
GIF animation
To assemble a set of PNG images (Dotplot_2012.png to Dotplot_2018.png) into a GIF animation,
I used the following “incantation” of ImageMagick:
The -delay 30 option sets a frame duration of 30/100 seconds, so about 3 images/s.
The result is nice but it is not possible to pause on a given year for a closer inspection.
Using a video file format instead of GIF, pausing would be possible, but a convenient way
to browse through the years would be much better.
Interactive dot plots with Altair/Vega
For a true interactive plot, I’ve played with Altair, the Python package based on the Vega/Vega-Lite JavaScript libraries.
It’s the second or third time I experiment with this library
(all the other plots are made with Matplotlib).
I find Altair appealing for its declarative programming interface
and the fact it is based on a sound visualization grammar. For example, it is based on a well-defined notion of visual encoding channels: position, color, shape…
For the present task, I wanted to explore more particularly the declarative description of interactivity, a feature added in late 2017/early 2018 with the release of Vega-Lite 2.0/Altair 2.0.
Here is the result, illustrated by a screencast video before I get to know
how to embed a Vega-Lite chart in WordPress:
Here fields=['year'] means that hovering one point will automatically select
all the data samples having the same year.
Then, the selection object is to be appended to one or several charts
(so that the selection works seamlessly across charts).
This is no more than calling .add_selection(selector) on each chart.
Finally, the selection is used to conditionally set the color of plotting marks,
or whatever visual encoding channel we may want to modify (size, opacity…).
A condition
takes a reference to the selection and two values: one for the selected case, the second when unselected.
Here is, for example, the complete specification of the bottom chart which
serves as a year selector:
years = base.mark_point(filled=True, size=100).encode(
x='year:O',
color=alt.condition(selector,
alt.value('green'),
alt.value('lightgray')),
).add_selection(selector)
The Vega-Lite compiler takes care of setting up all the input handling logic to make the interaction happen.
A few days ago, I happen to read a Matlab blog post on creating a linked selection
which operates across two scatter plots. As written in that post,
“there’s a bit of setup required to link charts like this, but it really
isn’t hard once you’ve learned the tricks”.
This highlights that the back-office work of the Vega-Lite compiler is
really admirable.
Notice that doing it in Python with Matplotlib would be equally verbose,
because it is not a matter of programming language but of imperative versus declarative plotting libraries.
Notes
Other discussions on dot plots
Here are the few other pages I found on Cleveland’s dot plots,
one with Tableau and one with R/ggplot:
I created the plots using RTE éCO₂mix
hourly records to generate the yearly statistics.
For a unknown reason, when I sum the powers over the year 2018,
I get slightly different values compared to RTE’s official 2018 statistical report on electricity (« Bilan Électrique 2018 »).
For example: Load 478 TWh vs 475.5 TWh, Wind 27.8 TWh vs 28.1 TWh…
I don’t like having such unexplained differences,
but at least they are small enough to be almost invisible in the plots.
Since the beginning of this WordPress blog/webpage, I've been using the Crayon syntax Highlighter plugin to enhance the display of small code extracts. Recently, a few days after publishing my small post on upgrading Julia, I discovered the page display was unfortunately broken. Only the post title was rendered and I had no idea why…
Screenshot of the blog post on Upgrading Julia, broken due to the Crayon syntax hightlighter plugin
Debugging a Worpress website
I had no experience with debugging a Worpress website. Fortunately, it turned out to be not that complicated. Searching for “Wordpress debug” quicky yield useful pages like How to Enable WordPress Debug or Debugging in WordPress. Setting two variables in the wp-config.php file was enough. I quickly saw logs full of mentions to the Crayon plugin. In particular one PHP Fatal error. Even without being a specialist, this didn't sound ok!
[16-Oct-2019 12:57:53 UTC] PHP Fatal error: Uncaught Error: Call to a member function id() on array in […]/blog/wp-content/plugins/crayon-syntax-highlighter/crayon_formatter.class.php:36
Stack trace:
0 […]/blog/wp-content/plugins/crayon-syntax-highlighter/crayon_formatter.class.php(538): CrayonFormatter::format_code('', Array, Object(CrayonHighlighter))
1 [internal function]: CrayonFormatter::delim_to_internal(Array)
2 […]/blog/wp-content/plugins/crayon-syntax-highlighter/crayon_formatter.class.php(516): preg_replace_callback('#()#msi', 'CrayonFormatter…', 'export PATH="/h…')
3 […]/blog/wp-content/plugins/crayon-syntax-highlighter/crayon_highlighter.class.php(166): CrayonFormatter::format_mixed_code('export PATH="/h…', Object(CrayonLang), Object(CrayonHighlighter))
4 […]/blog/wp-content/plugins/crayon-syntax-highlighter/crayon_highlighter.class.php(186): CrayonHighlighter->process()
5 […]/blog/wp-content/plugins/crayon-syntax-highlighter/crayon_wp.class.php( in […]/blog/wp-content/plugins/crayon-syntax-highlighter/crayon_formatter.class.php on line 36
After that diagnostic, it was just a matter of disabling the Crayon plugin and the website got back on track!
It happens that Crayon is unfortunately unmaintained these days. It is only testing against Worpress 4.2, while we are now in the 5.x series, and issues are piling up on GitHub. For the moment, I don't have searched for a replacement. All code extracts throughout the website display without syntax hightlighting, but at least they do display!
This is a short note on how to swiftly update Julia and IJulia (the kernel to work with Jupyter notebooks) when a new minor version is released. The following instructions are for Linux, with the example of upgrading from version 1.1 to version 1.2.
(remark: the existing StackOverflow question “How to upgrade Julia to a new release?” is very outdated, as of September 2019, and doesn’t cover Jupyter kernels)
Test in the shell command line: the julia command should now launch the new Julia REPL (at least after a shell restart).
Step 3: reinstall (and update) packages
Objective here is to reuse all the previously installed packages without the need to remember their names.
In the ~/.julia/environments directory, copy the Project.toml file from the previous version directory (ex: v1.1) and paste it in a directory named as the new version (ex: v1.2).
Now, in the Julia REPL, enter the Pkg REPL (pressing ]) and run update. If there is no new package version, there is no actual download happening. However, compiled packages like IJulia should be rebuilt.
Test: assuming that the IJulia packaged was included in Project.toml, the new Julia version should be available as a Jupyter kernel in the lab/notebook interface.
Remark: during my 1.4→ 1.6 update, the new kernelspec was not installed, so that I could not launch Julia 1.6 notebook. Perhaps there is no more automatic rebuilding of IJulia. So I forced the rebuild (in REPL: ]build IJulia).
Step 4: clean up the old Jupyter kernel
In the ~/.local/share/jupyter/kernels directory, there should be at least two directories: the one for the old Jupyter kernel (ex: julia-1.1) and the one for the new kernel (ex: julia-1.2). If the old kernel is not needed, it can be removed.
Notice: the kernel directories can be found with the $jupyter kernelspec list command.
(The directory of the old Julia binary can be deleted as well.)
Now that I'm back from SGE 2018 conference, I've put online the manuscript of my article and the slides of my presentation (in French).
“Gestion d'énergie avec entrées incertaines :
quel algorithme choisir ?
Benchmark open source sur une maison solaire”
The title in English (translation of the whole article in progress...) is:
“Energy management with uncertain inputs:
which algorithms ?
Open source benchmark based on a solar home”
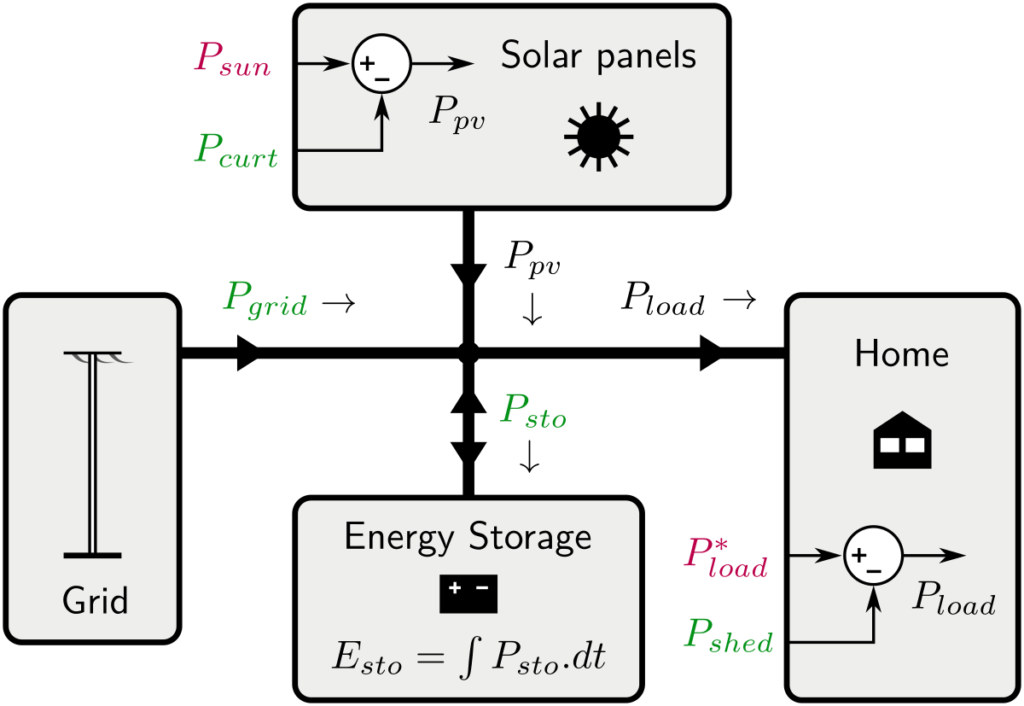
Here is the model of the solar home (power flows)
I've also a first translation of the abstract:
“Optimal management of energy systems requires strategies based on optimization algorithms. The range of tools is wide, and each tool calls on various theories (convex, dynamic, stochastic optimization...) which each require a period of appropriation ranging from a few days to several months.
It is therefore difficult for the novice energy management practitioner to understand the main characteristics of each approach so we can compare them objectively and finally find the method or methods best suited to a given problem.
To facilitate an objective and transparent comparison, we propose an exemplary and simple energy management problem: a solar house with photovoltaic production and storage. After justifying the sizing of the system, we illustrate the benchmark by a first comparison of some energy management methods (heuristic rule, MPC and anticipatory optimization). In particular, we highlight the effect of the uncertainty of solar production on performance.
This benchmark, including the management methods described, is open source, accessible online and multi-language (Python, Julia and Matlab).”
As of now, only rather simple energy management methods are implemented, but I'd like to add some kind of stochastic MPC (once I've clarified what this really means), and later Stochastic Dynamic Programming.
I've started exploring an open dataset that should be very useful for research on residential solar energy (for example studying energy self-consumption with a PV-battery system).
My Python code to manipulate this dataset and some preliminary studies (simple statistics) is freely available on Github: https://github.com/pierre-haessig/ausgrid-solar-data. This data exploration code is extensively using pandas (for slicing, grouping, resampling, etc.).
About the dataset
The “Solar home electricity dataset” is made available by Ausgrid, an Australian electric utility which operates the distribution grid in Sidney and nearby areas.
This dataset contains a pretty rich record:
electricity consumption and the PV production
of 300 customers (in Sidney and its area),
over three years (July 2010 to June 2013),
with a 30 minutes timestep.
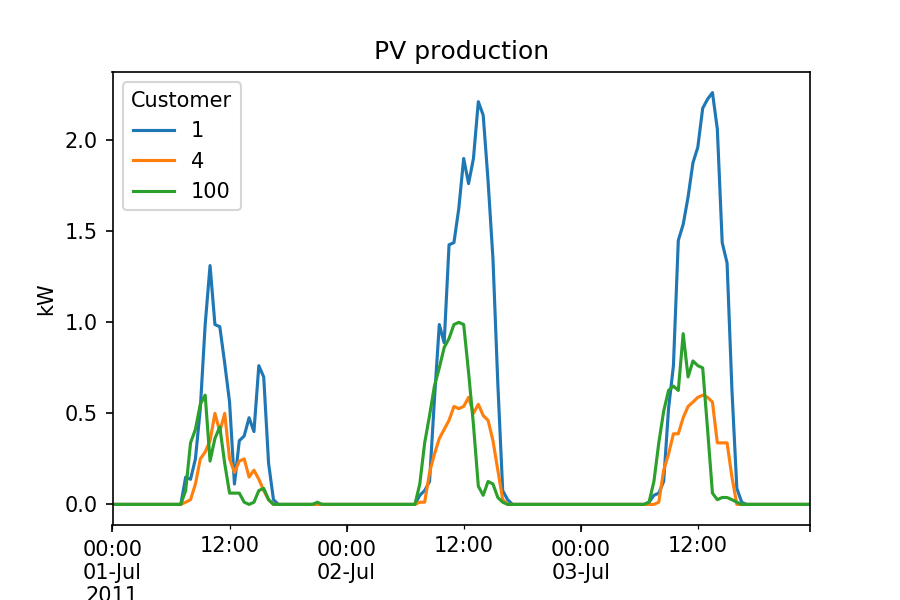
Here is a small extract of the PV production for 3 randomly chosen customers, over 3 days in July 2011:
Many more plots and statistics are given in the Jupyter notebooks available on the Github repository.
Locating postcodes (geocoding)
Also, the exploration of this dataset was an occasion to discover the Google Maps Geocoding API. Indeed, the location of each anonymous customer is given by a postcode only. To enable quantitative study of the spatiotemporal pattern in PV production, I've tried to locate this postcodes. The Python code for this is in the Postcodes location.ipynb Notebook. Map plotting is done with cartopy.
Extracted from this notebook, here is an overview of the locations of the postcodes present in the dataset (in Australia, NSW). Red rectangles are the boundaries of each postcode, as returned by Google maps (small in urban areas along the coast, gigantic otherwise).
2019-11-11 update: fixing broken link to dataset webpage on Ausgrid website.
To answer the repeating need to share advice on how to get an efficient Python setup for scientific computing and data analysis, I've created a dedicated page: Python setup for scientific computing.


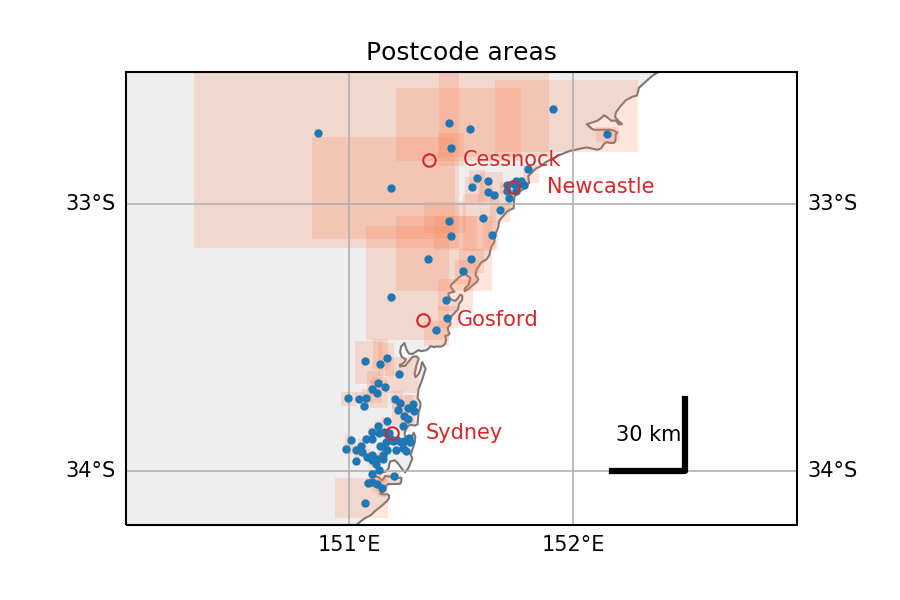 Extracted from this notebook, here is an overview of the locations of the postcodes present in the dataset (in Australia, NSW). Red rectangles are the boundaries of each postcode, as returned by Google maps (small in urban areas along the coast, gigantic otherwise).
Extracted from this notebook, here is an overview of the locations of the postcodes present in the dataset (in Australia, NSW). Red rectangles are the boundaries of each postcode, as returned by Google maps (small in urban areas along the coast, gigantic otherwise).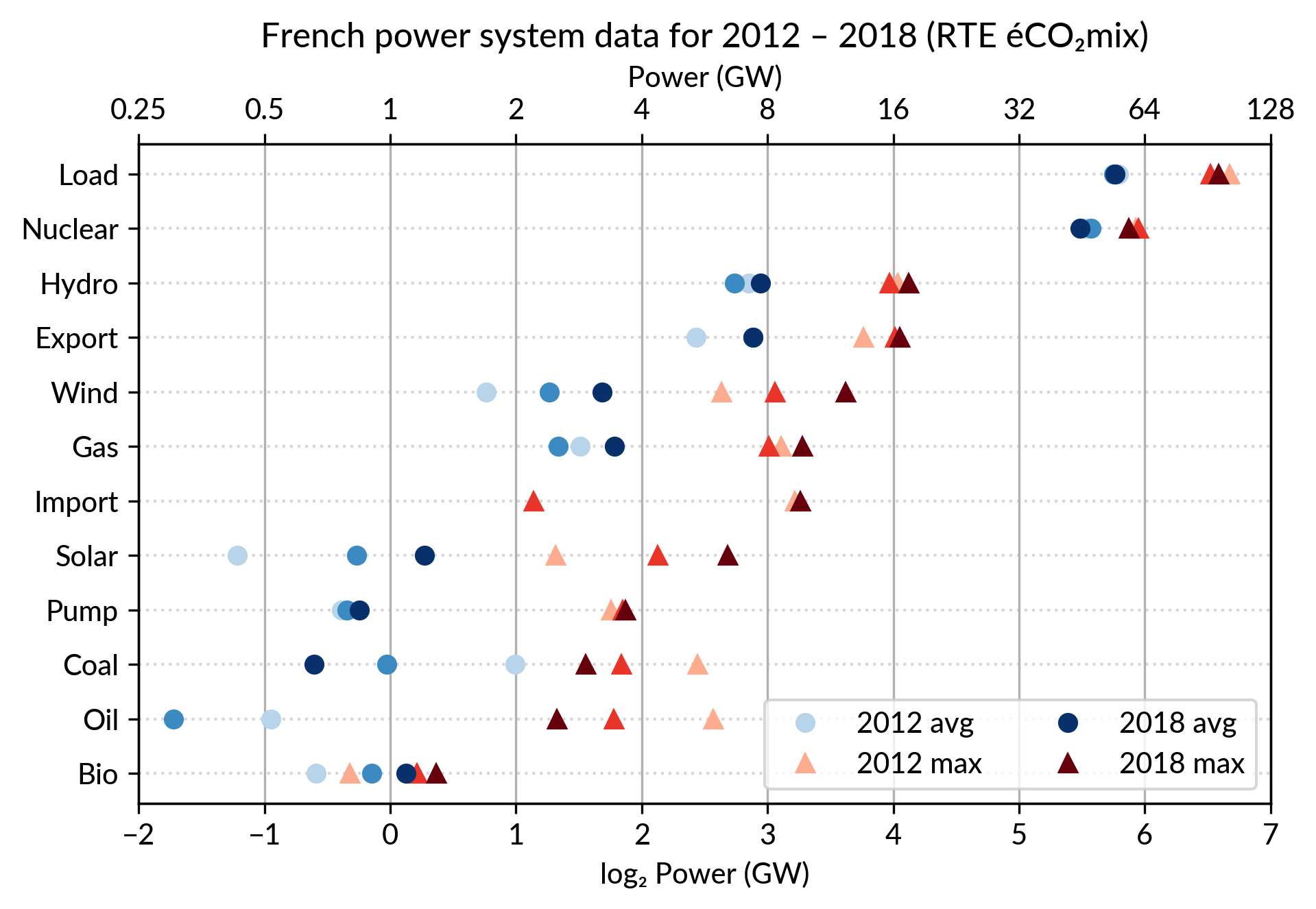{kind=link}