You can think of a fully charged battery as a source of energy, ready to sell its product to the electric grid, just the way a power plant does. For that to work, battery owners would need to buy electricity to charge the battery when the price is low, and then sell that electricity back to the grid when the price is high.
But that idea turns out to be a dud.
Not many articles in mass media or in scientific journals take the time to explain how useful batteries can be to integrate renewables. But fewer also explains, like this NPR post, that batteries, at their currentcost and capabilities, are not ready for the massive deployment on the grid that is predicted by some.
Fortunately, there is much on-going research on battery technology (and on other storage technologies as well). The progress on batteries has been tremendous and steady since their invention (e.g. the impressive improvement of electric model aircraft since 70s), so there may still be technological leaps to come.
This is the title of a blog post by Jake Vanderplas, researcher in Astronomy & Machine Learning at University of Washington. He points out that conducting successful research requires more and more data manipulation skills, going along programming skills. However, in academia, ability to write good software is not promoted, if not discouraged !
"academia has been singularly successful at discouraging these very practices that would contribute to its success"
"any time spent building and documenting software tools is time spent not writing research papers, which are the primary currency of the academic reward structure"
On the other hand, software skills are very important and thus well rewarded in the industry, thus the idea of "Big Data Brain Drain" which pumps talented young graduates out of academic research.
After the diagnosis
Jake's post is the "medical diagnosis", and each disease calls for a treatment ! Since the problem is sociological/organizational, the treatment must be sociological/organizational. Jake lays 4 propositions, in particular the evolution of research evaluation criteria. Of course the "implementation details" of evaluation are always a tough issue, not only for research (thinking of learning and teaching evaluation here).
But in general, I hope that the recognition of good software will change positively, along with the general issue of reproducibility. In fact, I think that many academics are aware of the issue, but they just don't see the practical track to recover from the current "dead end" (and also senior researcher don't have much time to thoroughly work on the issue) :
"Making an openly available program for electrical machine sizing would be immensely useful for our research community! It would summarize 20 years of research of our group. I just don't take/find the time for it."
This is an (approximate & very shortened) transcript of the reaction of Hamid Ben Ahmed, one of my PhD advisor when discussing the topic this week. This means that in the field Electrical Engineering (which is has been tied for decades with closed source softwares like Simulink or 3D finite elements models) the feeling that "something is not working" is already there, and that's a good start!
Pushing the change
Now, it is all about academics pushing "le Système" (i.e. French academia), and not waiting for the change to come "from the top". Indeed, I feel that top-level research directors have too many other things to deal with, like managing huge research consortium, writing huge evaluation reports, ... no time for "far away issues" such as reproducibility 😉
Let's just push !
PS : not all of the electrical engineering research runs on closed software. See for example the open source work of Prof. Bernard Uguen and his team on radio wave propagation : www.pylayers.org (from IETR, a neighbor lab of Rennes University 1)
Just recently going through Fernando Perez' G+, I went across several links on open science and reproducibility of science.
One blog post about the non-evolution of Elsevier publishing policies. As a result, Greg Martin, a mathematician in Vancouver, has decided to resign from the editorial board of Elsevier’s Journal of Number Theory.
I found also two blog posts by Matthew Brett on the NiPy blog ("NeuroImaging with Python" community) about Unscientific Programming and the Ubiquity of Error in computing. The latter asserts that computing tools in science lead easily to results with many mistakes (not to mention the recent discussion about Excel spreadsheets mistakes). From my experience in computing for science, I very much agree with this fact. Often those mistakes are small though (i.e. the order of magnitude of the result is preserved), but not always...
From my research...
Matthew Brett blog reminded of a pretty bad example of error in computing that I encounter when working on my last conference paper dealing with the modeling of a sodium-sulfur battery (cf. PowerTech article on my publications page).
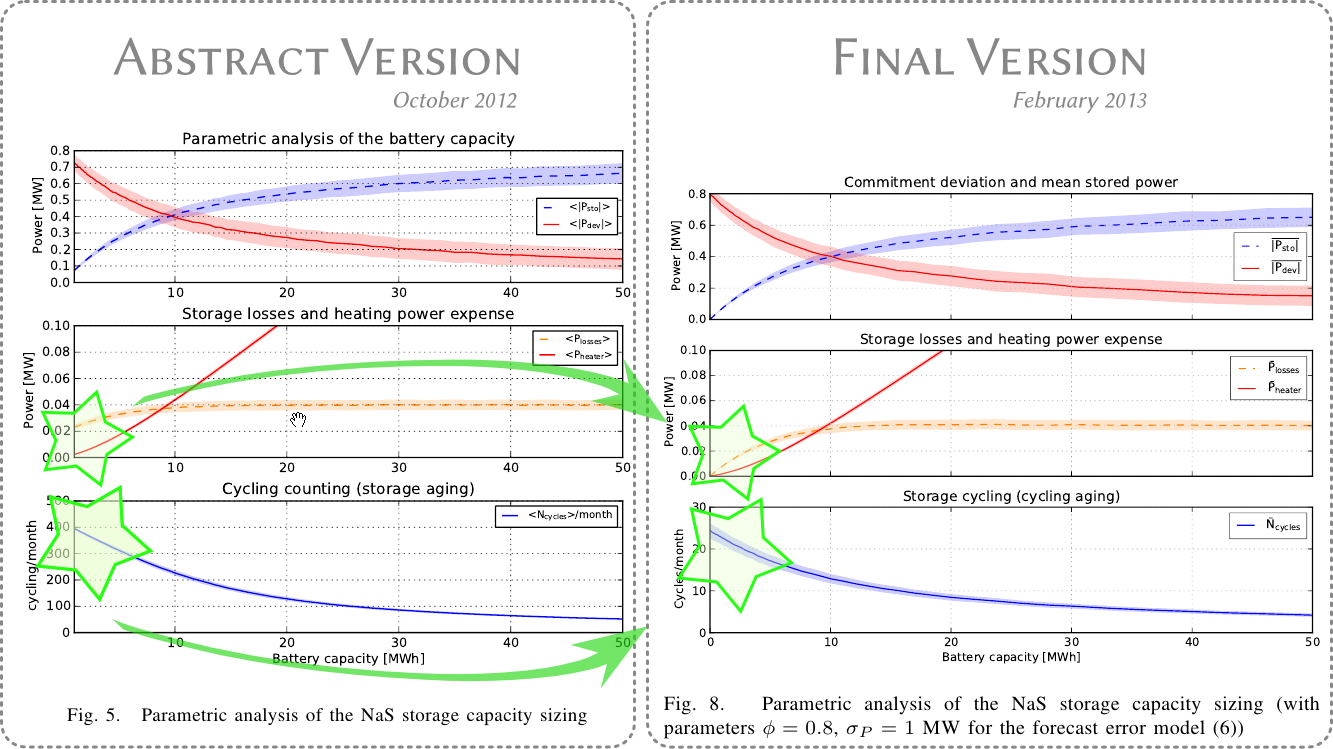
Just in time for the deadline, I submitted a "long abstract" in October 2012. I had just finished implementing the model of the battery and the simulation was up and running. One of the main figure presenting the results is copied here :
Evolution of a figure in my article between Abstract and Final version
and now the interesting thing is to compare the October 2012 version to the February 2013 version (submission of the full paper). Beyond surface changes in the annotations, I've highlighted two big differences in the results. The most striking change is in the lower pane : the "cycle counting" drops from about 400 down to 25 cycles/month. One order of magnitude less !
What happened in the meantime...
Without entering the details, there were several really tiny errors in the implementation of the model. I would not even call these erros "bugs", those were just tiny mistakes. One was somehow like writing Q += i instead of Q += i*dt (omitting the time step when counting electric charges). And when the time step dt is 0.1, that's makes an easy method to miss exactly one order of magnitude ! Spotting those errors in fact takes quite some time and probably one or two weeks were devoted to debugging in November (just after the submission of the abstract).
Of course, reviewers have almost no way to spot this error. First the code is not accessible (the battery model is confidential) and second, the value that was wrong (cycle counting) cannot be easily checked with a qualitative reasoning.
Since I don't know how to solve the problem from the reviewer point of view, let's get back to my position : the man who writes the wrong code. And let's try to see how to make this code a little better.
Testing a physical simulation code
There is one thing which I feel makes model simulation code different from some other codes: it is the high number of tests required to check that it works well. Even with only 3 state variables and one input variable like the sodium-sulfur battery, there are quite a lot of combinations.
I ended up asking the code to report the evolution the mode on one single time step in this ASCII art fashion :
and to cover enough situations, I have in fact 6 text files containing each 5 blocks like this one. That's 30 tables to check manually, so that's still doable, but there is no easy way to tell "oh, that -15,107 over there doesn't looks right"... it just take time and a critical eye (the latter is the most difficult to get).
Freeze the test for the future
If I now want to upgrade the battery simulation code, I want to ensure that the time spent by my thesis advisor and I on the result checking is not lost.I want to enforce that the code always generates the exact same numerical result.
This is the (somehow dirty) method I've used : run the same test, generate the ASCII string, and compare the result with a previous run stored in a text file. I pasted the code here so that the word "dirty" gets an appropriate meaning :
def test_single_step_store(T_mod, N_cycles, write_test=False):
'''test the NaSStorage.store_power() method on a single timestep
and compare with results saved in files
"test/NaSStorage single step test Tnnn.txt"
each test is run for a given Temperature and N_cycles,
for a predefined range of
* State of Energy [0, 0.001, 0.5, 0.999, 1]
* Power requests [-99e3,-14.14e3, -10e3, 0 , 10e3, 14.14e3, 99e3]
'''
SoE_list = [0, 0.001, 0.5, 0.999, 1]
P_req_list = [-99e3,-14.14e3, -10e3, 0 , 10e3, 14.14e3, 99e3]
# Run the series of tests
header = 'Test of `NaSStorage.store_power` at '+\
'T_mod={:03.1f}, N_cycles={:04.0f}'.format(T_mod, N_cycles)
print(header)
res = header + '\n'
for SoE in SoE_list:
res += single_step_analysis(SoE, T_mod, N_cycles, P_req_list,
dt=0.1, display=False)
res += '\n'
import io
test_fname = '80 test/NaSStorage single step test '+\
'T{:04.0f}-N{:04.0f}.txt'.format(T_mod*10, N_cycles)
# Write test results
if write_test:
from datetime import datetime
with io.open(test_fname,'w') as res_file:
res_file.write('NaSStorage test file generated on %s\n' % \
datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
res_file.write(res)
# Read test results
with io.open(test_fname) as res_file:
res_file.readline() # skip the date header
res_cmp = res_file.read()
print('Comparing with recorded test "%s"' % test_fname)
test_ok = (res_cmp == res)
print('Comparison test OK!' if test_ok else 'There are differences in the test:')
#assert test_ok
### Print the differences with red color:
if not test_ok:
from termcolor import colored
res_list = [c if c == res_cmp[i] else colored(c, 'red', attrs = ['bold'])
for i,c in enumerate(res) if i<len(res_cmp)]
print(''.join(res_list))
Now, hopefully the simulation code is doing what it should and there won't be a third version of the figure in my article... Hopefully !
I just put online the material of my Python training class I taught yesterday for the first time to a group of ~15 science teachers at my school ENS Rennes. It is a new requirement of the French Education Ministry that these teachers (in Math, Physics and Engineering) will have to teach Programming and Numerical computing with Python, starting next academic year in September 2013. They can otherwise choose Scilab, which can be useful for playing with block diagrams.
Since the targeted audience was mainly composed of Mechanical Engineering teachers, I tried to anchor several examples in that field. Nothing "advanced" though, because I'm not a mechanical engineer ! And more importantly, those examples were meant to be ready-to-use, for teachers to be soon in front of their new students. I hope they found this useful !
I just finished the book "les marchands de doute" ("Merchants of Doubt") by Naomi Oreskes et Erik M. Conway. It took me some weeks because I read so sparsely, but I'm glad I did.
Since by nature I like thinking in terms of doubts, I know I could get easily influenced by some skeptical arguments on Global warming. Arguments read or heard every now and then from friends, colleagues or randomly on the internet. Indeed, I think that the "Cartesian doubt" approach is fruitful when approaching a new research topic.
However, the book "Merchants of Doubt" sheds the light on an unfruitful kind of doubt I was unaware of: the unfair doubt, the doubt on a topic where a reasonable scientific consensus is already reached, the doubt that is overly supported by people which feels threatened by those scientific results. Such doubt is purported beyond reason in order to give a false impression to the general public. The impression that there is still an active scientific debate when this debate is actually long gone (or moved to minor details of the question).
I believe "Merchants of Doubt" is the outcome of a tremendous work of historical research from its authors. Naomi Oreskes et Erik M. Conway show the unexpected connection between the doubt on the dangers of Tobacco, Pesticides, Ozone depletion and Climate change in general. Indeed, it's quite incredible to learn that some of the people who were constantly harassing scientific results (and sometimes scientists themselves!) on those pretty different topics were actually the same people!
Just as a pointer, Naomi Oreskes and Jacques Treiner (translator of the French edition) were invited on the radio program Science publique just a year ago, when the French edition was published.
As a result this reading, I have now downloaded some of the IPCC reports on Climate change! I doubt I'll take the time to read those entirely, but my first very positive impression was on how clear their writing is. Figures are clearly presented and there is a very systematic approach in the treatment of uncertainty (since there is always some) by the use of a precisely defined vocabulary (like "Virtually certain", "Extremely likely", "More likely than not", depending on clearly expressed probability thresholds). This is clearly in contrast to the crude approach of the "Merchants of Doubt"...