Just recently going through Fernando Perez' G+, I went across several links on open science and reproducibility of science.
One blog post about the non-evolution of Elsevier publishing policies. As a result, Greg Martin, a mathematician in Vancouver, has decided to resign from the editorial board of Elsevier’s Journal of Number Theory.
I found also two blog posts by Matthew Brett on the NiPy blog ("NeuroImaging with Python" community) about Unscientific Programming and the Ubiquity of Error in computing. The latter asserts that computing tools in science lead easily to results with many mistakes (not to mention the recent discussion about Excel spreadsheets mistakes). From my experience in computing for science, I very much agree with this fact. Often those mistakes are small though (i.e. the order of magnitude of the result is preserved), but not always...
From my research...
Matthew Brett blog reminded of a pretty bad example of error in computing that I encounter when working on my last conference paper dealing with the modeling of a sodium-sulfur battery (cf. PowerTech article on my publications page).
Just in time for the deadline, I submitted a "long abstract" in October 2012. I had just finished implementing the model of the battery and the simulation was up and running. One of the main figure presenting the results is copied here :
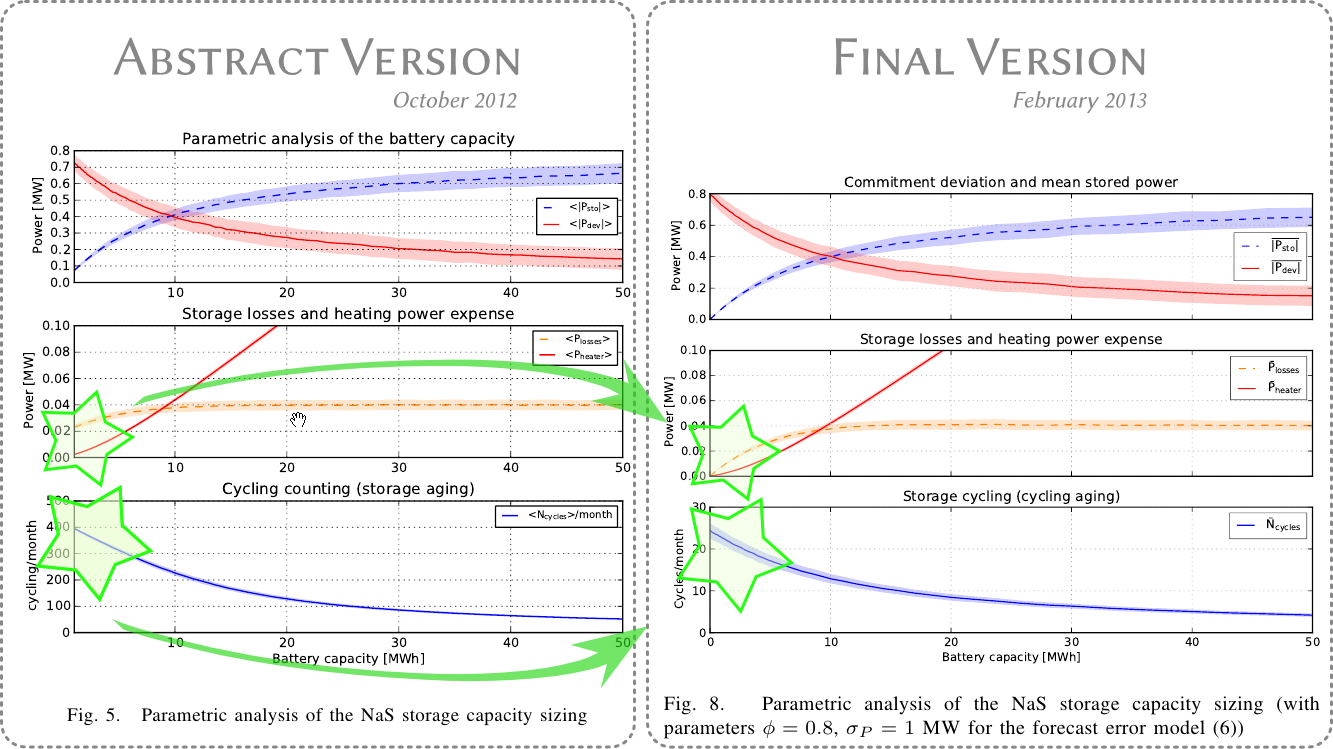
and now the interesting thing is to compare the October 2012 version to the February 2013 version (submission of the full paper). Beyond surface changes in the annotations, I've highlighted two big differences in the results. The most striking change is in the lower pane : the "cycle counting" drops from about 400 down to 25 cycles/month. One order of magnitude less !
What happened in the meantime...
Without entering the details, there were several really tiny errors in the implementation of the model. I would not even call these erros "bugs", those were just tiny mistakes. One was somehow like writing Q += i instead of Q += i*dt (omitting the time step when counting electric charges). And when the time step dt is 0.1, that's makes an easy method to miss exactly one order of magnitude ! Spotting those errors in fact takes quite some time and probably one or two weeks were devoted to debugging in November (just after the submission of the abstract).
Of course, reviewers have almost no way to spot this error. First the code is not accessible (the battery model is confidential) and second, the value that was wrong (cycle counting) cannot be easily checked with a qualitative reasoning.
Since I don't know how to solve the problem from the reviewer point of view, let's get back to my position : the man who writes the wrong code. And let's try to see how to make this code a little better.
Testing a physical simulation code
There is one thing which I feel makes model simulation code different from some other codes: it is the high number of tests required to check that it works well. Even with only 3 state variables and one input variable like the sodium-sulfur battery, there are quite a lot of combinations.
I ended up asking the code to report the evolution the mode on one single time step in this ASCII art fashion :
------ State at t0 ------
SoE| DoD_c| T_mod| N_cyc
0.500| 282.5| 305.0| 0.0
(dt=0.100 h)
: ------------ Power flows [W] --------- | - State evolution -
P_req : P_sto | P_emf | P_heat| P_Joul| P_invl| ΔDoD | ΔT_m |100 ΔN
-99,000 : -47,619|-53,230| +0| +3,230| +2,381| +6.68| +0.27|+0.620
-14,140 : -14,140|-15,107| +1,676| +260| +707| +1.90| +0.00|+0.176
-10,000 : -10,000|-10,629| +1,915| +129| +500| +1.33| +0.00|+0.124
+0 : +0| +0| +2,300| +0| +0| +0.00| +0.00|+0.000
+10,000 : +10,000| +9,408| +2,435| +92| +500| -1.18| +0.00|+0.110
+14,140 : +14,140|+13,251| +2,437| +182| +707| -1.66| +0.00|+0.154
+99,000 : +52,632|+47,645| +1,093| +2,355| +2,632| -5.98| +0.00|+0.555
and to cover enough situations, I have in fact 6 text files containing each 5 blocks like this one. That's 30 tables to check manually, so that's still doable, but there is no easy way to tell "oh, that -15,107 over there doesn't looks right"... it just take time and a critical eye (the latter is the most difficult to get).
Freeze the test for the future
If I now want to upgrade the battery simulation code, I want to ensure that the time spent by my thesis advisor and I on the result checking is not lost.I want to enforce that the code always generates the exact same numerical result.
This is the (somehow dirty) method I've used : run the same test, generate the ASCII string, and compare the result with a previous run stored in a text file. I pasted the code here so that the word "dirty" gets an appropriate meaning :
def test_single_step_store(T_mod, N_cycles, write_test=False):
'''test the NaSStorage.store_power() method on a single timestep
and compare with results saved in files
"test/NaSStorage single step test Tnnn.txt"
each test is run for a given Temperature and N_cycles,
for a predefined range of
* State of Energy [0, 0.001, 0.5, 0.999, 1]
* Power requests [-99e3,-14.14e3, -10e3, 0 , 10e3, 14.14e3, 99e3]
'''
SoE_list = [0, 0.001, 0.5, 0.999, 1]
P_req_list = [-99e3,-14.14e3, -10e3, 0 , 10e3, 14.14e3, 99e3]
# Run the series of tests
header = 'Test of `NaSStorage.store_power` at '+\
'T_mod={:03.1f}, N_cycles={:04.0f}'.format(T_mod, N_cycles)
print(header)
res = header + '\n'
for SoE in SoE_list:
res += single_step_analysis(SoE, T_mod, N_cycles, P_req_list,
dt=0.1, display=False)
res += '\n'
import io
test_fname = '80 test/NaSStorage single step test '+\
'T{:04.0f}-N{:04.0f}.txt'.format(T_mod*10, N_cycles)
# Write test results
if write_test:
from datetime import datetime
with io.open(test_fname,'w') as res_file:
res_file.write('NaSStorage test file generated on %s\n' % \
datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
res_file.write(res)
# Read test results
with io.open(test_fname) as res_file:
res_file.readline() # skip the date header
res_cmp = res_file.read()
print('Comparing with recorded test "%s"' % test_fname)
test_ok = (res_cmp == res)
print('Comparison test OK!' if test_ok else 'There are differences in the test:')
#assert test_ok
### Print the differences with red color:
if not test_ok:
from termcolor import colored
res_list = [c if c == res_cmp[i] else colored(c, 'red', attrs = ['bold'])
for i,c in enumerate(res) if i<len(res_cmp)]
print(''.join(res_list))
Now, hopefully the simulation code is doing what it should and there won't be a third version of the figure in my article... Hopefully !