Dans le cadre de la Journée Nouvelles Technologies du CCMO, j'ai fait une présentation intitulée "Enjeux énergétiques par le prisme d'objets du quotidien". Voici les diapos (pdf).
Cette présentation était à destination d'enseignants de science en lycée. L'idée était d'utiliser des objets de la vie courante (bouilloire, frigo) pour rendre plus concrètes les notions d'énergie et de puissance. Exemple : une batterie de téléphone portable ≈ 5 Wh. En matérialisant ces notions, on peut aider à construire un regard actif/critique sur l'enjeu citoyen qu'est l'énergie.
La présentation comprend aussi une comparaison entre 2 moyens de production autonome d'électricité : groupe électrogène et panneaux photovoltaïques. Coût d'investissement faible pour le groupe électrogène, mais coût élevé du carburant. C'est bien sûr l'inverse pour le solaire : investissement onéreux, mais "carburant" gratuit.
Pour l'analyse de la ressource solaire, j'ai utilisé les graphiques et les données de PVGIS (Photovoltaic Geographical Information System).
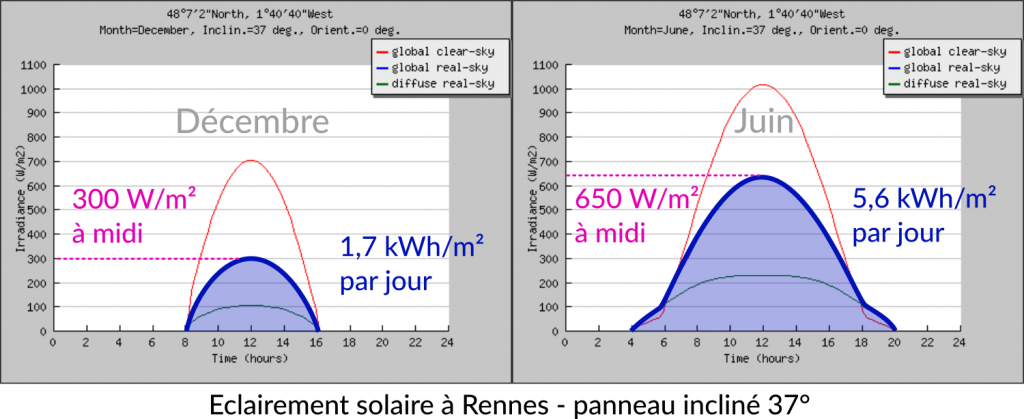
Au final en moyenne annuelle, on peut espérer 4 kWh/m²/jour soit 1450 kWh/m²/an. Par rapport au sud de la France, Rennes n'est donc pas si défavorisée, puisqu'on n'atteint en Côte d'Azur "que" 2000 kWh/m²/an (cf. la jolie carte du potentiel de solaire de la France).
Par ailleurs, en préparant cette présentation, je suis tombé sur le blog richement alimenté "Do the Math" de Tom Murphy, professeur à University of California, San Diego, et qui creuse justement la question des enjeux de l'énergie.