This week, I was trying to get a deep understanding of the necessary conditions for the appearance of contiguous periods ("long strokes") of negative prices in electricity spot markets. Such strokes appeared for example last weekend (5 Apr 2026).
For this study, I've created a toy economic dispatch, with as few parameters as possible. Indeed the goal is certainly not to recreate a complicated twin of the real power markets but instead only summon the simplest elements which are needed to cause the phenomenon.
My core assumption, waiting to be refuted, is that negative system prices can appear even when the marginal costs of all plants in the system are positive or zero. I suppose that inflexibility (e.g. block orders) should suffice. Is this indeed the case?
As of now, with only two power plants (base: cheap but inflexible and peak: flexible but expensive), the dispatch model can reproduce isolated negative marginal price events (see video capture), which occur at the single instant(s) supporting the curtailment of the base plant due to its inflexibility. However, this model cannot reproduce a sequence of consecutive negative price instants.
Adding free solar electricity makes up for more colorful graphs and generates long strokes of zero marginal price, but not strictly negative.
So my question/challenge is: what does it take to reproduce long strokes of negative prices?
A full-blown day-ahead power market model? Hopefully not!
Introducing binary (ON/OFF) decisions or other non-convexities? Perhaps, is it necessary to reproduce single negative price instants?
A larger, more diverse, fleet of power plants? Perhaps even a number as large the number of consecutive negative instants to be reproduced?
These last weeks, I’ve read William S. Cleveland book “The Elements of Graphing Data”.
I had heard it’s a classical essay on data visualization.
Of course, on some aspects, the book shows its age (first published in 1985), for example
in the seemingly exceptional use of color on graphs.
Still, most ideas are still relevant and I enjoyed the reading.
Some proposed tools have become rather common, like loess curves.
Others, like the many charts he proposes to compare data distributions (beyond the common histogram),
are not so widespread but nevertheless interesting.
One of the proposed tools I wanted to try is the (Cleveland) dot plot.
It is advertised as a replacement of pie charts and (stacked) bar charts, but with a greater visualization power.
Cleveland conducted scientific experiments to assess that superiority, but it’s not detailed in the book (perhaps it is in the Cleveland & McGill 1984 paper).
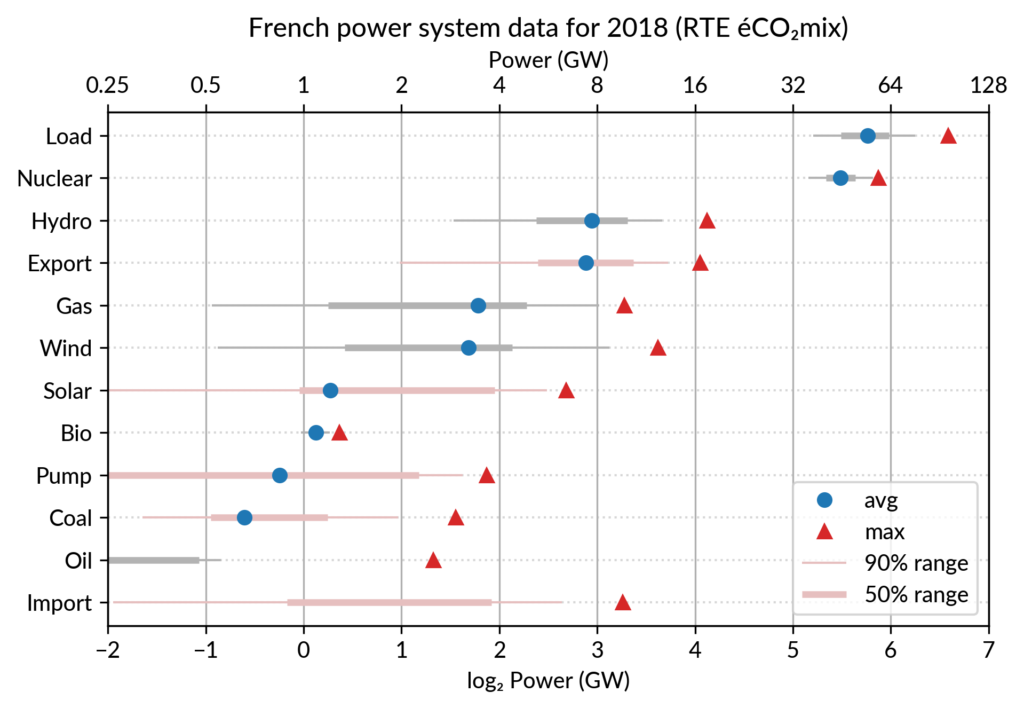
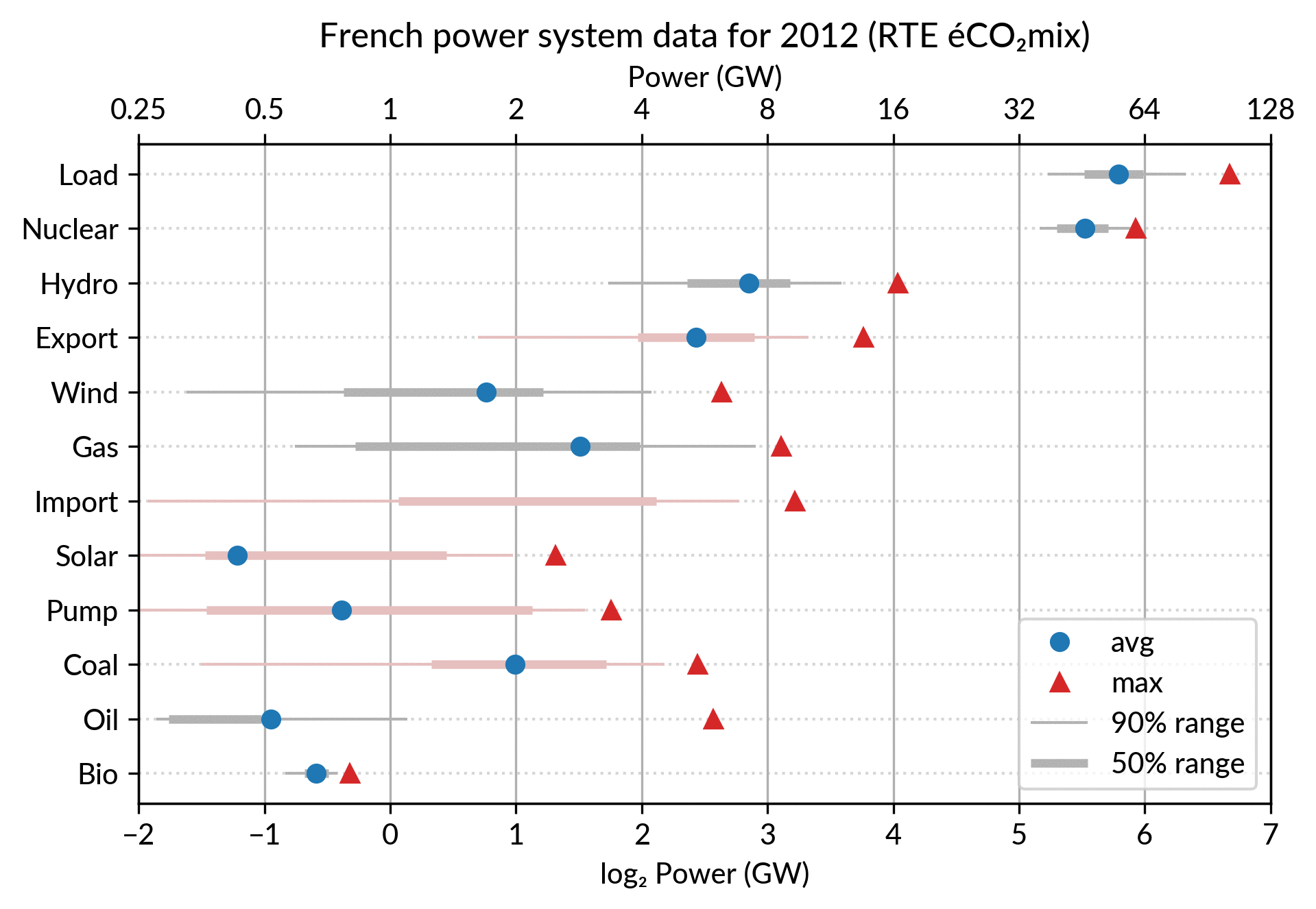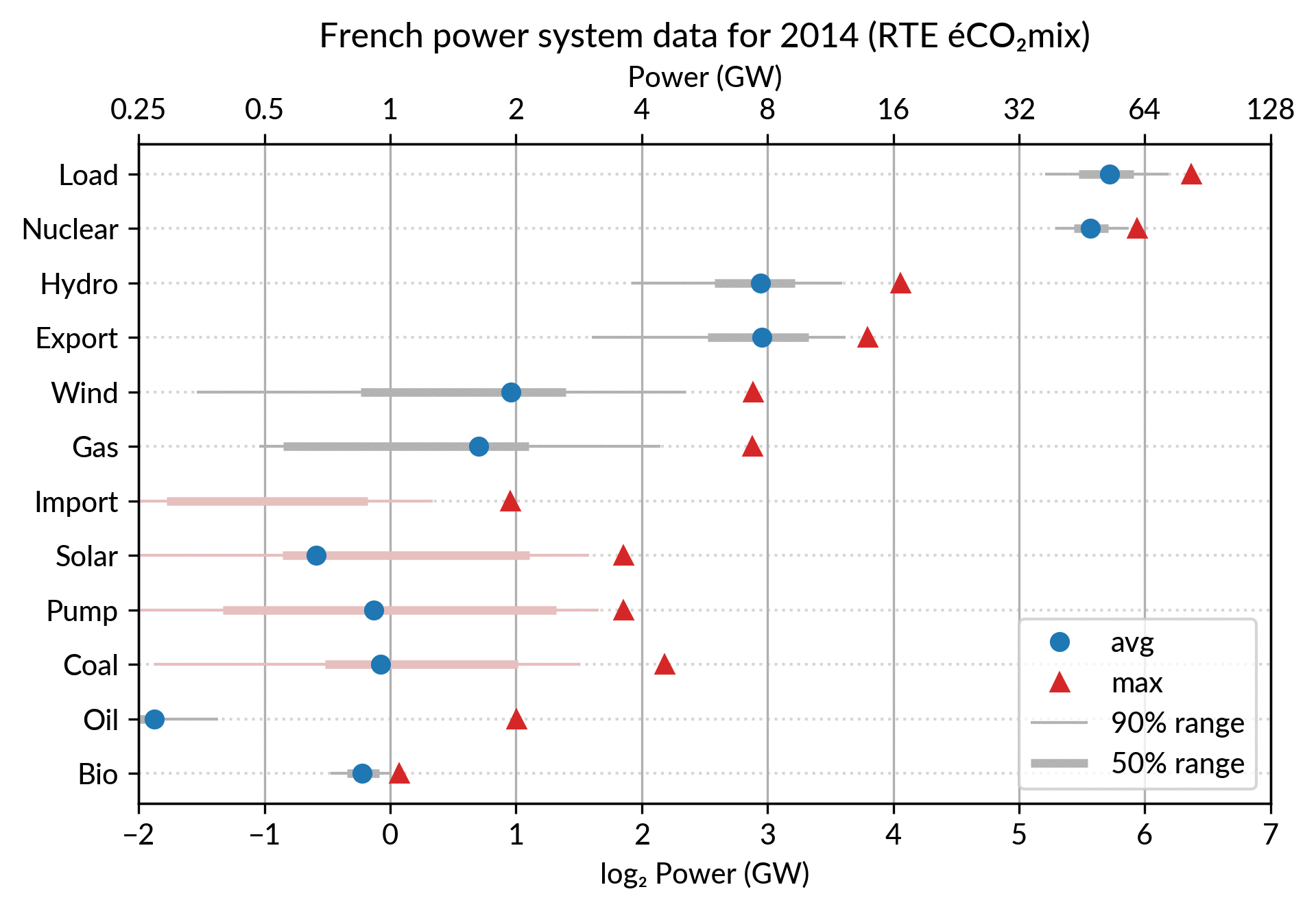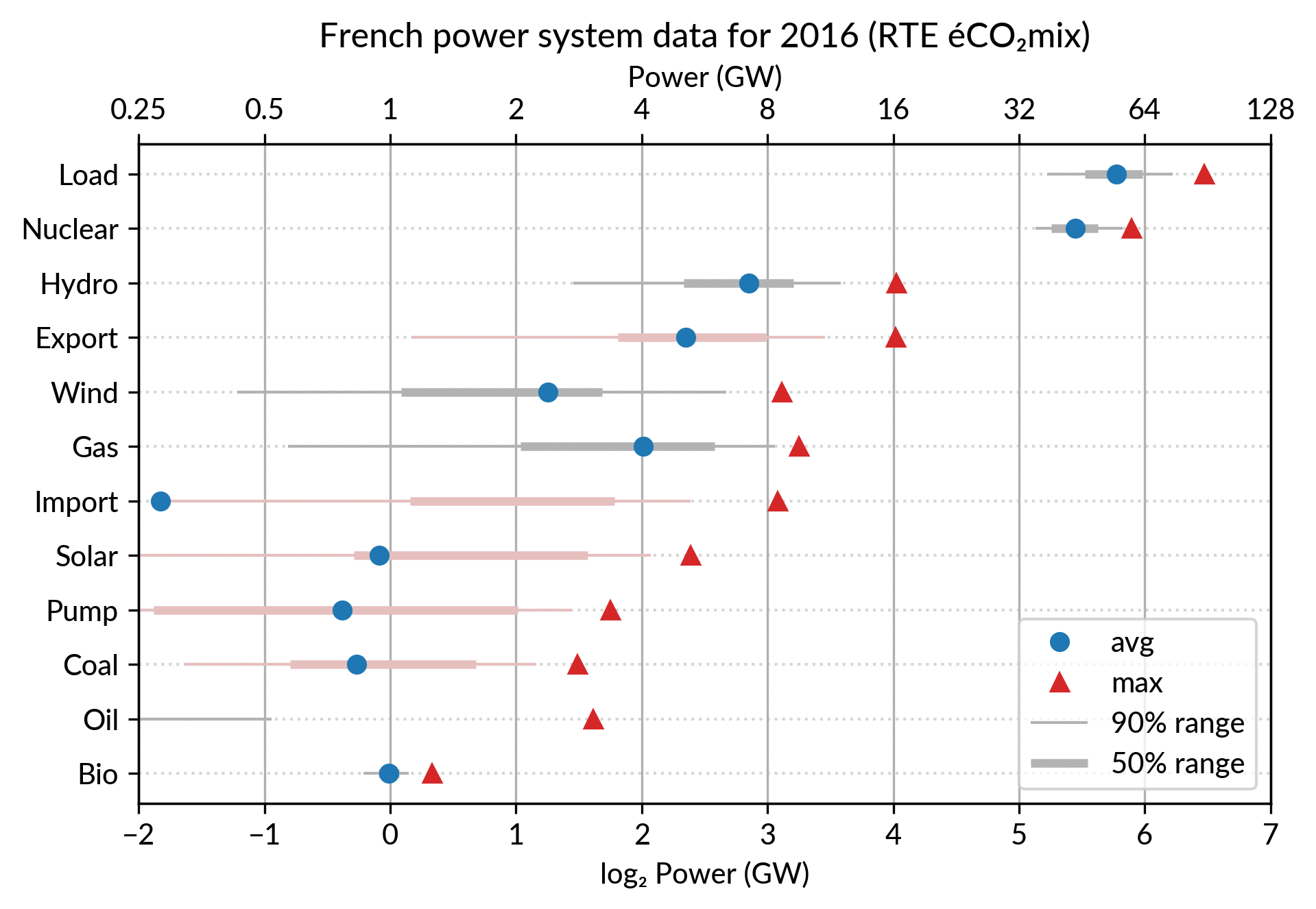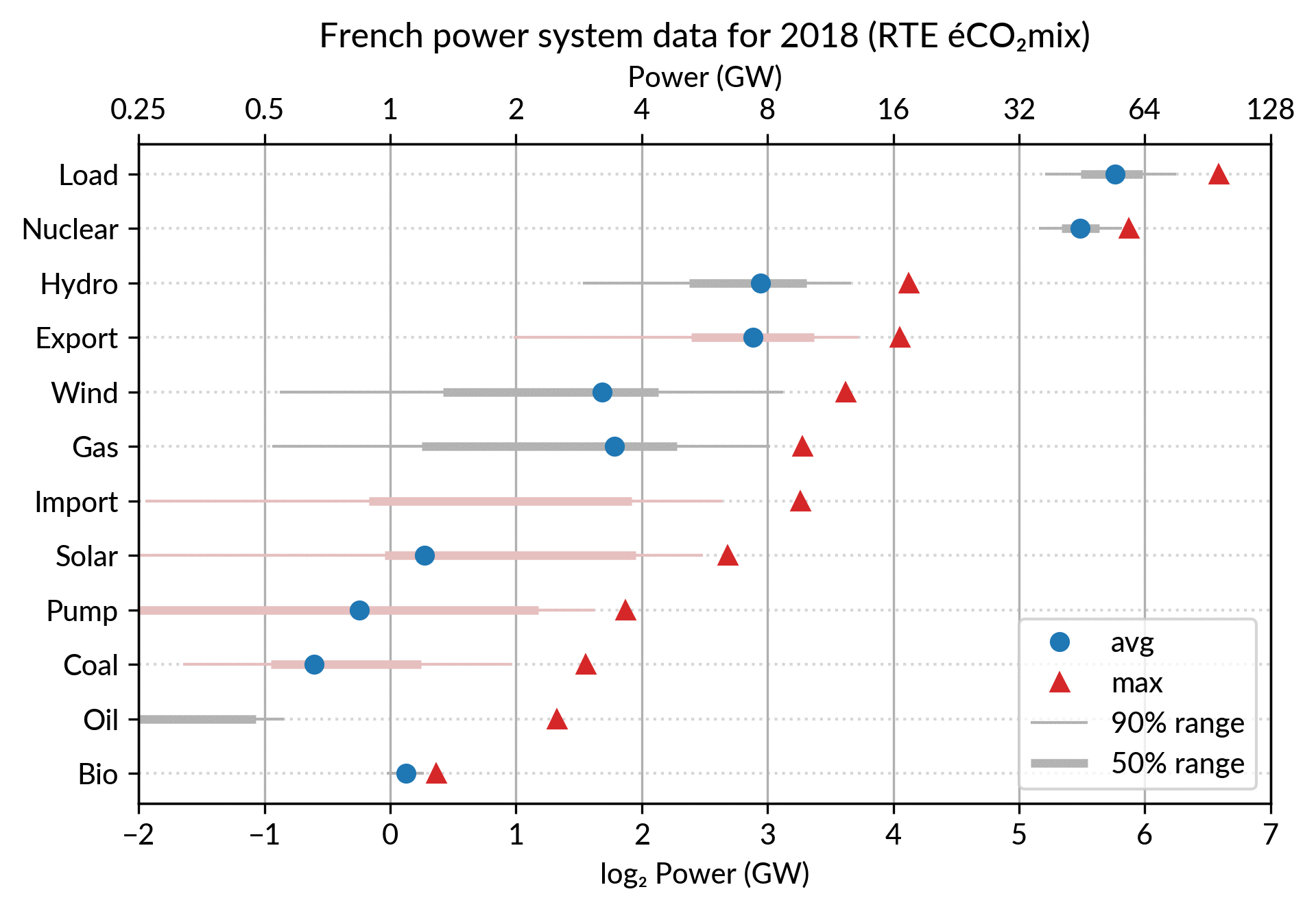
I’ve explored the visualization power of dot plots using the French electricity data from RTE éCO₂mix (RTE is the operator of the French transmission grid).
I’ve aggregated the hourly data to get yearly statistics similar to RTE’s yearly statistical report on electricity (« Bilan Électrique »).
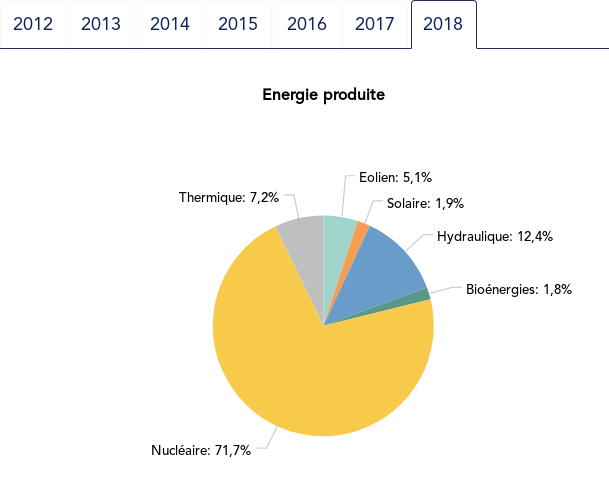
The case for dot plot
Such yearly energy data is typically represented with pie charts to show the share of each category of power plants. This is RTE’s pie chart for 2018 (from the Production chapter):
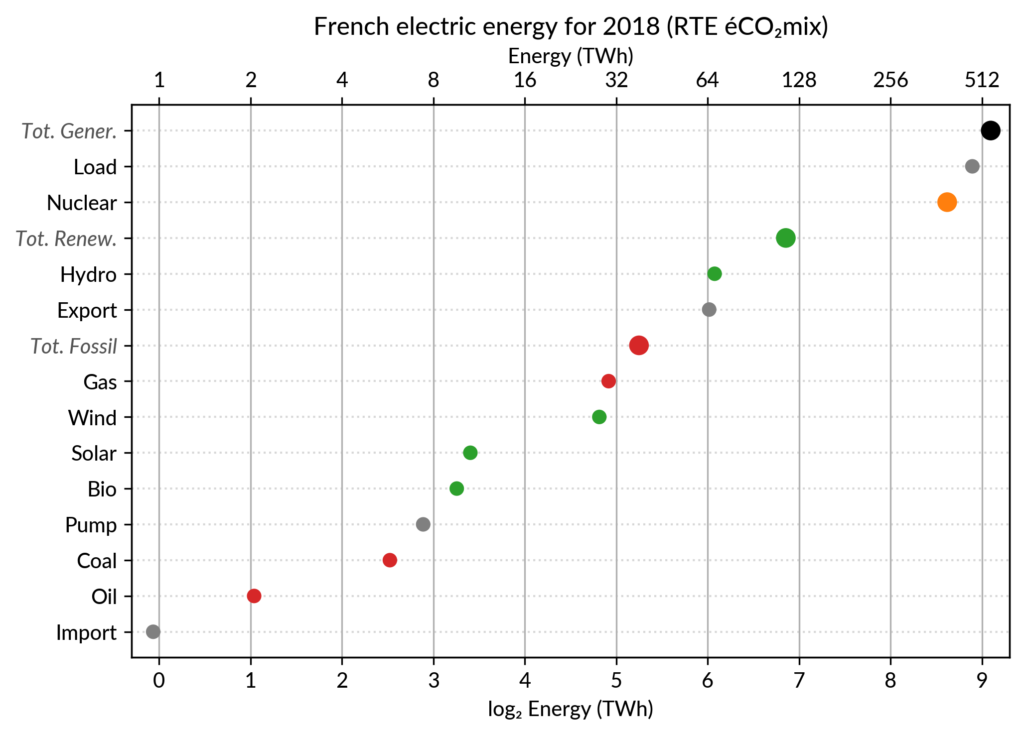
However, Cleveland claims that the dot plot alternative enables more efficient reading of single point values
and also easier comparison of different points together. Here is the same data shown with a simple dot plot:
I’ve colored plant types by three general categories:
Fossil (gas, oil and coal) in red
Renewable (hydro, wind, solar and bioenergy) in green
Nuclear in orange
Subtotals for each category are included.
Gray points are either not a production (load, exports, pumped hydro) or cannot be categorized (imports).
Compared to the pie chart, we benefit from the ability to read the absolute values rather than just the shares.
However, how to read those shares?
This is where the log₂ scale, also promoted by Cleveland in his book, comes into play. It serves two goals. First, like any log scale, it avoids the unreadable clustering of points around zero
when plotting values with different orders of magnitude.
However, Cleveland specifically advocates log₂ rather than the more
common log₁₀ when the difference in orders of magnitude is small (here
less than 3, with 1 to 500 TWh) because it would yield a too small
number of tick marks (1, 10, 100, 1000 here) and also because log₂ aids reading ratios of two values:
a distance of 1 in log₂ scale is a 50% ratio
a distance of 2 in log₂ scale is a 25% ratio
…
Still, I guess I’m not the only one unfamiliar with this scale, so I made myself a small conversion table:
Δlog
ratio a/b (%)
ratio b/a
0.5
71% (~2/3 to 3/4)
1.4
1
50% (1/2)
2
1.5
35% (~1/3)
2.8
2
25% (1/4)
4
3
12%
8
4
6%
16
5
3%
32
6
1.5%
64
As an example, Wind power (~28 TWh) is at distance 2 in log scale of
the Renewable Total, so it is about 25%. Hydro is distant by less than
1, so ~60%, while Solar and Bioenergies are at about 3.5 so ~8% each.
Of course, the log scale blurs the precise value of large
shares. In particular, Nuclear (distant by 0.5 to the total generation)
can be read to be somewhere between 65% and 80% of the total, while the
exact share is 71.2%. The pie chart may seem more precise since
the Nuclear part is clearly slightly less than 3/4 of the disc.
However, Cleveland warns us that the angles 90°, 180° and 270° are
special easy-to-read anchor values whereas most other values are in fact
difficult to read.
For example, how would I estimate the share of Solar in the pie chart
without the “1.9%” annotation? On the log₂ scaled dot plot, only a
little bit of grid line counting is necessary to estimate the distance
between Solar and Total Generation to be ~5.5, so indeed about 2% (with
the help of the conversion table…).
The bar chart alternative?
Along with the pie chart, the other classical competitor to dot plots is the bar chart.
It’s actually a stronger competitor since it avoids the pitfall of the poorly readable angles of the pie chart.
I (with much help from Cleveland) see three arguments for favoring dots over bars.
The weakest one may be that dots create less visual clutter. However, I see a counter-argument that bars are more familiar to most viewers, so if it were only for this, I may still prefer using bars.
The second argument is that the length of the bars would be meaningless.
This argument only applies when there is no absolute meaning for the
common “root” of the bars. This is the case here with the log scale. It
would also be the case with a linear scale if, for some reason, the zero
is not included.
The third argument is an extension of the first one (better clarity) in the case when several data points for each category must be compared. Using bars there are two options:
drawing bars side by side: yields poor readability
stacking bars on top of each other (if the addition makes
sense like votes in an election): makes a loss of the common ground,
except for the bottom most bars (of left most bars when using the
horizontal layout like here)
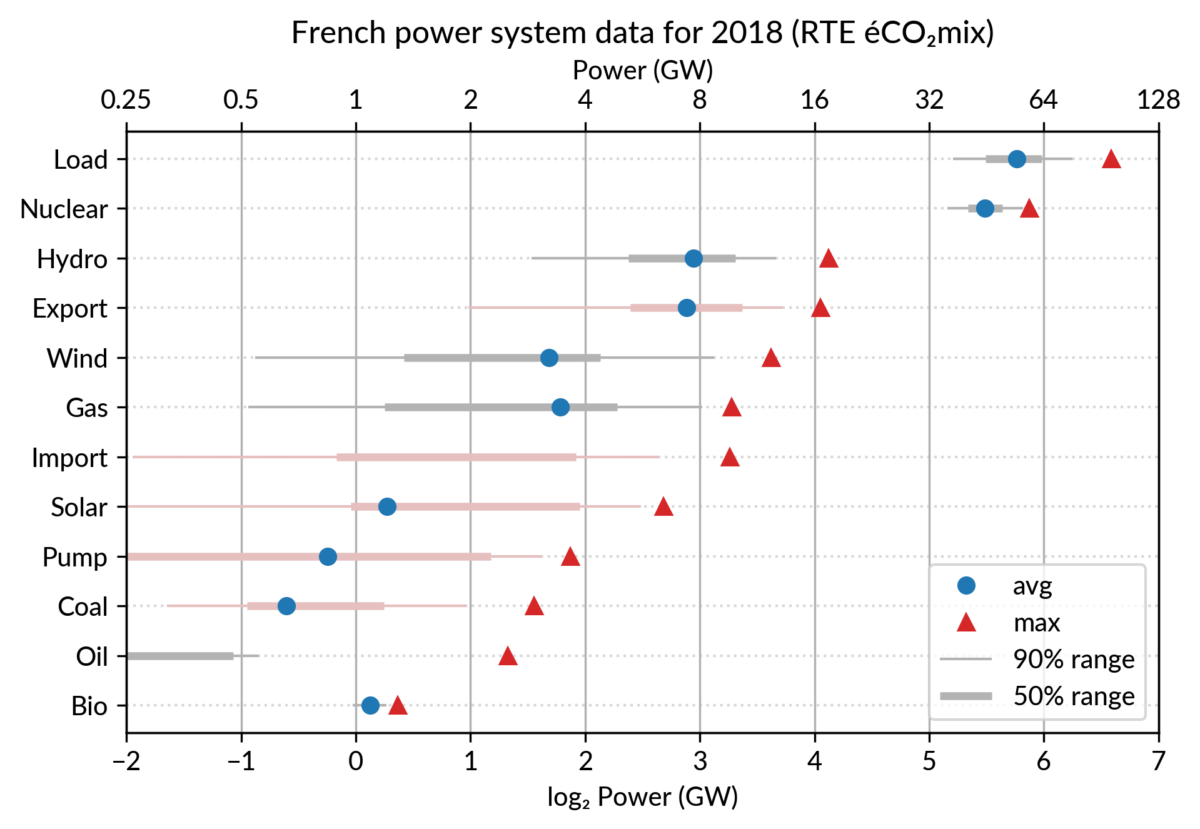
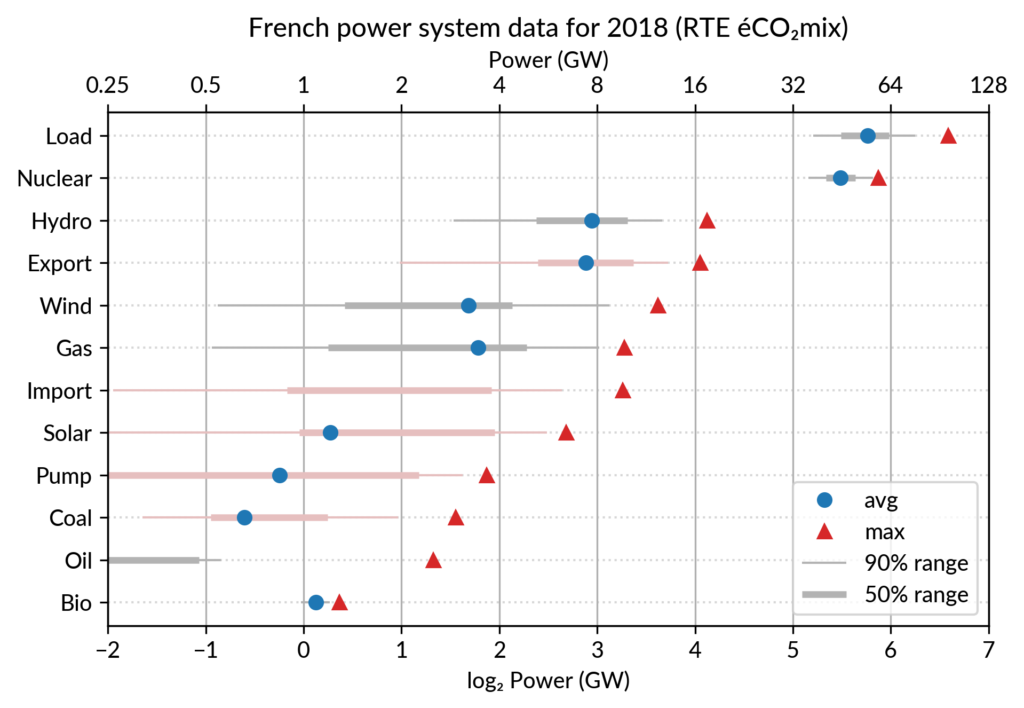
This brings me to the case where dot plots shine most: multiway dot plots.
Multiway dot plots
The compactness of the “dot” plotting symbol (regardless of the
actual shape: disc, square, triangle…) compared to bars allows
superposing several data points for each category.
Cleveland presents multiway dot plots mostly by stacking horizontally
several simple dot plots. However, now that digital media allows high
quality colorful graphics, I think that superposition on a single plot
is better in many cases.
For the electricity data, I plot for each plant category:
the maximum power over the year (GW): red triangles
the average power over the year (GW): blue discs
The maximum power is interesting as a proxy to the power capacity.
The average power is simply the previously shown yearly energy production data, divided by the duration of the year.
The benefit of using the average power is that it can be superimposed
on the plot with the power capacity since it has the same unit.
Also, the ratio of the two is the capacity factor of the plant category, which is a third interesting information.
Since it is recommended to sort the categories by value (to ease comparisons), there are two possible plots:
plot sorted by the maximum powers (~capacity)
plot sorted by the average powers (equivalent to the cumulated energy for the year)
The two types of sorts are slightly different (e.g. switch of Wind and Gas) and I don’t know if one is preferable.
Adding some quantiles
Since I felt the superposition of the max and average data was
leaving enough space, I packed 4 more numbers by adding gray lines
showing the 90% and 50% range of the power distribution over the year.
With these lines, the chart starts looking like a box plot, albeit pretty non-standard.
However, I faced one issue with the quantiles: some plant categories
are shut down (i.e. power ≤ 0) for a significant fraction of the year:
Solar: 52% (that is at night)
Coal: 29% in 2018
Import: 96% (meaning that the French grid was net-importing electricity from its neighbors only 4% of the year in 2018)
To avoid having several quantiles clustered at zero, I chose to
compute them only for the running hours (when >0). To warn the
viewer, I drew those peculiar quantiles in light red rather than gray.
Spending a bit more time, it would be possible to stack on the right a
second dot plot showing just the shutdown times to make this more
understandable.
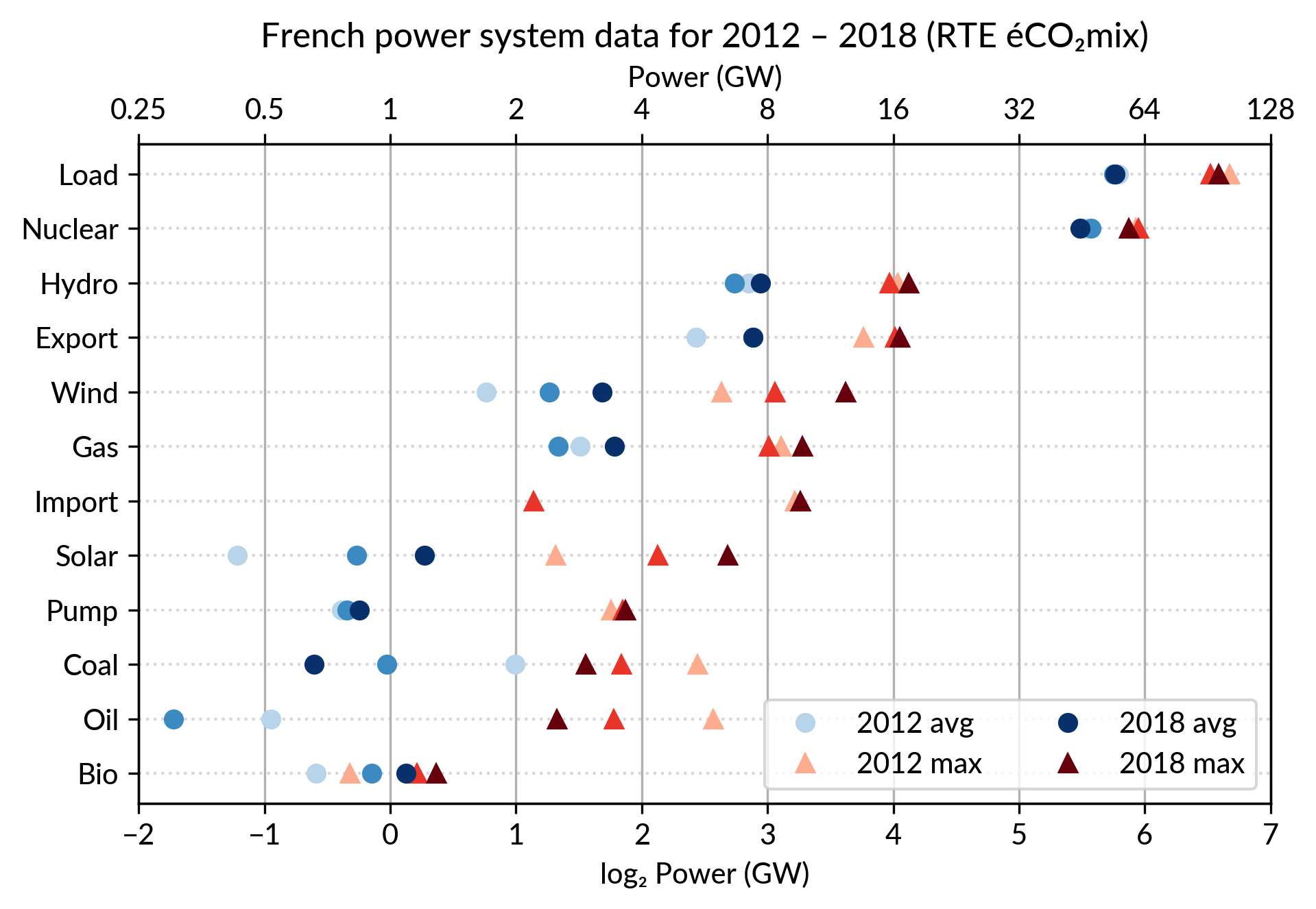
Animated dot plots
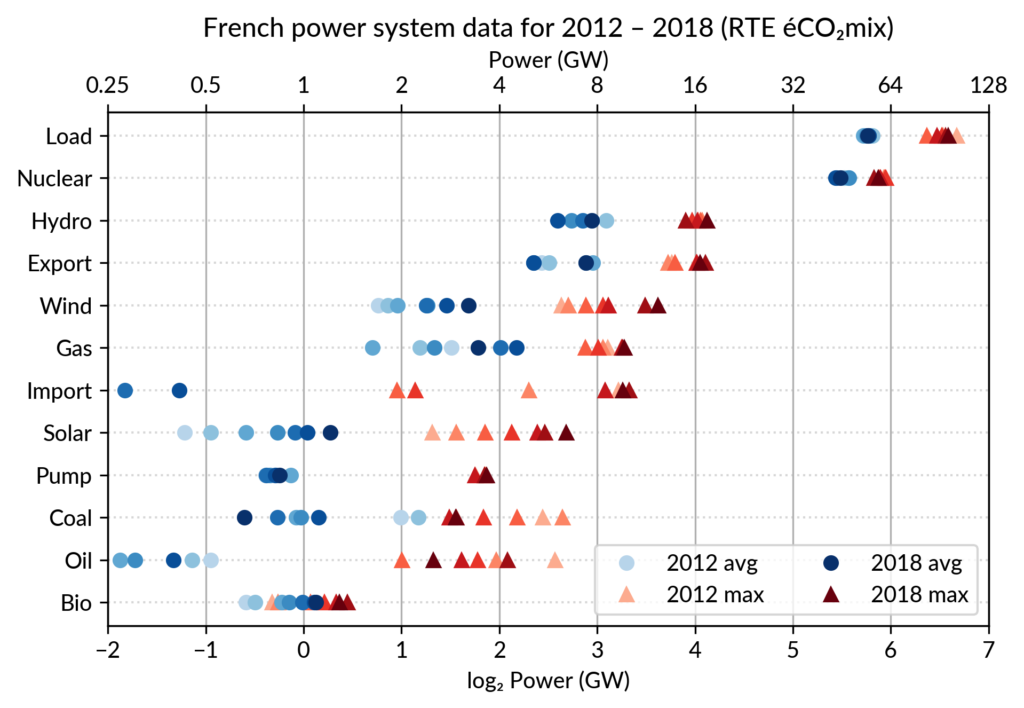
Again trying to pack more data on the same chart, I superimposed the statistics for several years.
RTE’s data is available from 2012 to 2018 (2019 is still in the making…) and the year can be encoded by the lightness of the dots.
I think it is possible to perceive interesting information from this
chart (like the rise of Solar and Wind along the drop of Coal), but it
may be a bit too crowded.
With only two or three years (e.g. 2012-2015- 2018), it is fine though.
A better alternative may be to use an animation. I tried two solutions:
GIF animation generated from the sequence of plots for each year
Interactive plot with the highlight of each year with mouse interaction using Altair
GIF animation
To assemble a set of PNG images (Dotplot_2012.png to Dotplot_2018.png) into a GIF animation,
I used the following “incantation” of ImageMagick:
The -delay 30 option sets a frame duration of 30/100 seconds, so about 3 images/s.
The result is nice but it is not possible to pause on a given year for a closer inspection.
Using a video file format instead of GIF, pausing would be possible, but a convenient way
to browse through the years would be much better.
Interactive dot plots with Altair/Vega
For a true interactive plot, I’ve played with Altair, the Python package based on the Vega/Vega-Lite JavaScript libraries.
It’s the second or third time I experiment with this library
(all the other plots are made with Matplotlib).
I find Altair appealing for its declarative programming interface
and the fact it is based on a sound visualization grammar. For example, it is based on a well-defined notion of visual encoding channels: position, color, shape…
For the present task, I wanted to explore more particularly the declarative description of interactivity, a feature added in late 2017/early 2018 with the release of Vega-Lite 2.0/Altair 2.0.
Here is the result, illustrated by a screencast video before I get to know
how to embed a Vega-Lite chart in WordPress:
Here fields=['year'] means that hovering one point will automatically select
all the data samples having the same year.
Then, the selection object is to be appended to one or several charts
(so that the selection works seamlessly across charts).
This is no more than calling .add_selection(selector) on each chart.
Finally, the selection is used to conditionally set the color of plotting marks,
or whatever visual encoding channel we may want to modify (size, opacity…).
A condition
takes a reference to the selection and two values: one for the selected case, the second when unselected.
Here is, for example, the complete specification of the bottom chart which
serves as a year selector:
years = base.mark_point(filled=True, size=100).encode(
x='year:O',
color=alt.condition(selector,
alt.value('green'),
alt.value('lightgray')),
).add_selection(selector)
The Vega-Lite compiler takes care of setting up all the input handling logic to make the interaction happen.
A few days ago, I happen to read a Matlab blog post on creating a linked selection
which operates across two scatter plots. As written in that post,
“there’s a bit of setup required to link charts like this, but it really
isn’t hard once you’ve learned the tricks”.
This highlights that the back-office work of the Vega-Lite compiler is
really admirable.
Notice that doing it in Python with Matplotlib would be equally verbose,
because it is not a matter of programming language but of imperative versus declarative plotting libraries.
Notes
Other discussions on dot plots
Here are the few other pages I found on Cleveland’s dot plots,
one with Tableau and one with R/ggplot:
I created the plots using RTE éCO₂mix
hourly records to generate the yearly statistics.
For a unknown reason, when I sum the powers over the year 2018,
I get slightly different values compared to RTE’s official 2018 statistical report on electricity (« Bilan Électrique 2018 »).
For example: Load 478 TWh vs 475.5 TWh, Wind 27.8 TWh vs 28.1 TWh…
I don’t like having such unexplained differences,
but at least they are small enough to be almost invisible in the plots.
You can think of a fully charged battery as a source of energy, ready to sell its product to the electric grid, just the way a power plant does. For that to work, battery owners would need to buy electricity to charge the battery when the price is low, and then sell that electricity back to the grid when the price is high.
But that idea turns out to be a dud.
Not many articles in mass media or in scientific journals take the time to explain how useful batteries can be to integrate renewables. But fewer also explains, like this NPR post, that batteries, at their currentcost and capabilities, are not ready for the massive deployment on the grid that is predicted by some.
Fortunately, there is much on-going research on battery technology (and on other storage technologies as well). The progress on batteries has been tremendous and steady since their invention (e.g. the impressive improvement of electric model aircraft since 70s), so there may still be technological leaps to come.
Thanks to the publicly available RTE éCO2mix data about French electricity, I was able to analyze the French electricity consumption since June 24th 2000 (15 minutes time-step averages), that is a bit more than 11 years. This is the first data analysis based on my éCO2mix downloading tool I announced a few days ago. It shows the tremendous increase (44 %) in the peak consumption value over this period.
Note : tools (Python script) and data that generated these curves and tables are openly available on GitHub.
Consumption evolution
To get a glimpse at what is going on with French electricity consumption, here is a plot over those 11 years.
French electricity consumption : weekly averages, with records pointed with red diamonds
How to read this plot
The read line shows weekly averages so that weekly and daily variations are smoothed out.
The light blue shaded region which is the range between min and max consumption during the given week. This gives an idea of intra-week variability that the red curve doesn't show.
The red diamonds shows the successive consumption records (see below)
Pattern and trend
On this plot, one can see the seasonal consumption pattern which is basically:
less consumption during summers
more consumption during winters
The reason for this being roughly that there is a bigger need for heating and lightning during winter than during summer.
Also, there is a general increasing trend. More precisely, one can see that consumption during summer is just slowing increasing, while winter demand is getting bigger and bigger. I will now illustrate this with the analysis of consumption records.
Consumption records
I searched for successive records in the consumption data (starting June 2000). I found 27 records ("I" being my Python code...) which are all listed in the table below. All records (but one) happened around 7pm in winter, that is during the so called "evening peak", when people come back home and put both heating and lighting on (and start watching TV...).
Also, all these records happened during weekdays other than Saturday or Sunday. This is related to the weekly pattern which contains a significant drop on weekends.
A tremendous increase of peak demand
If I summarize these successive records over the years, here is what I get :
During Winter 2000-2001, the highest peak was 70.5 GW (at 7pm on Tuesday January 9th, 2001)
During Winter 2005-2006, the highest peak was 86.2 GW (at 7pm on Friday January 27th 2006)
During Winter 2011-2012 an historical record was set at 101.7 GW (at 7pm on Wednesday February 8th, 2012)
This is +44 % increase in peak demand, which I feel is quite huge over this not-so-long period of 11 years. This requires the commissioning of new dedicated power plants to avoid black outs during winter.
Rationale for this increase
I'm not a specialist of this topic, but the basic idea is that this tremendous increase is French specific (if compared to similar European countries like Germany or UK).
It comes from the fact that a high proportion of house heating is electric (around 30 %, and even more in new buildings). Each new building with an electric heating system is prone to be an additional peak load during winter, and they are a lot.
This is summarized by the "thermal sensitivity" of French electricity consumption : there is an increase of +2.3 GW each time the outside air temperature goes down by 1°C. In Germany, it is only +0.5 GW...
And why do French people rely so much on electric heating ? Perhaps because of the price and also the culture of "cheap nuclear electricity". French regulated price for electrical energy is about 0.11 €/kWh for residential customers (including taxes). The regulated price has been frozen for some years by the French government to avoid angering people. Also, the installation cost of electric heaters is lower than of a fuel/gas based central heating system.
However, in my opinion, French electricity price is bound to increase of maybe 30 % in the coming years, partly due to the need to either stop or rebuild nuclear power plants. It is sad that a lot of peoplee who will have to pay this extra cost where trapped in the first place by an artificially low electricity price.
Electricity consumption peaks table
French electricity consumption peaks between June 2000 and February 2012 (demand records computed with 15 minutes averages)
RTE, the French Transmission system operator (TSO) launched in November 2010 the éco2mix web application where real-time updated data about the French electricity market (national consumption + detailed production) was made publicly available. Their Flash application displays this information nicely, but the raw data is also available for download, which is far more interesting...
I've started writing simple tools (Python-based) to download this data set and then process it. As of now, these tools are openly available on a GitHub repository. Various custom plotting functions should follow.
Interestingly enough, the éco2mix website proposes data only up to one month prior the current date. However, it appeared that the underlying data server can serve daily files as early as year 1900 ! Only those files are quite empty... 😉
The real daily data files are available starting June 26th 2000, but those only contain the national electricity consumption, along with the D-1 consumption forecast. The detailed electricity production data (Nuclear, Hydro, Wind, ...) has been only available since about 2010, that is when the éco2mix application was launched.
")
{kind=link}